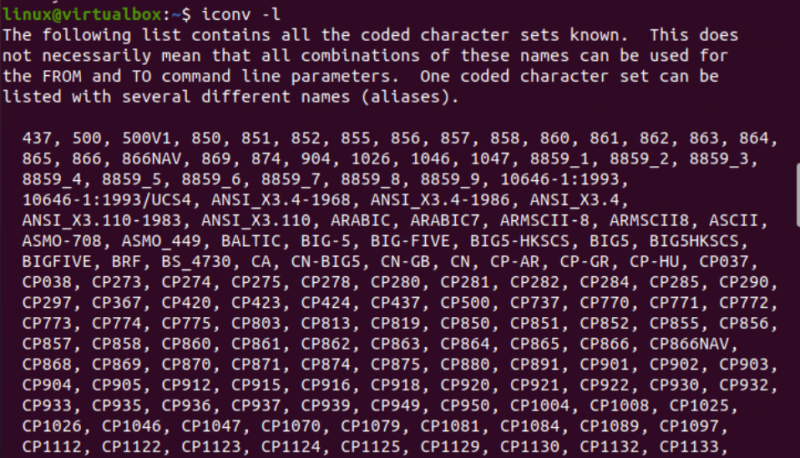
Oglejmo si zdaj pripomoček iconv Linuxa v njegovi terminalski konzoli. Tako smo izvajali navodilo “iconv” z zastavico “-l” za prikaz vseh znanih in najpogosteje uporabljenih naborov kodiranih znakov na našem terminalskem zaslonu. Prikazal bo kodirane nabore znakov skupaj z njihovimi vzdevki. Ko se nekoliko pomaknete navzdol, lahko vidite dolg seznam kodiranih naborov znakov.
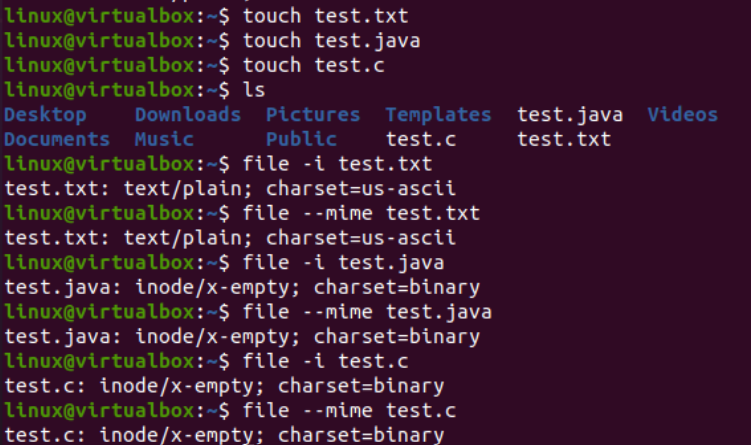
Zdaj je čas, da začnemo z implementacijo ukaza iconv v Linuxu. Najprej potrebujemo različne vrste datotek v našem sistemu za pretvorbo ene vrste datoteke v drugo. Tako uporabljamo poizvedbo »dotik« na terminalu konzole za ustvarjanje treh različnih datotek, tj. vrste Java, vrste C in vrste besedila. Če izpišete trenutno vsebino imenika, boste v njem našli novo ustvarjene datoteke.
Po tem si bomo ogledali vrsto vsake datoteke posebej z uporabo poizvedbe »datoteka« skupaj z imenom vsake datoteke. Ta poizvedba potrebuje možnost »-I« za prikaz vrste nabora znakov za kodiranje za vsako datoteko posebej. Če ste pozabili uporabiti možnost »-I«, namesto tega uporabite zastavico »—mime«. Zastavici »-I« in »—mime« delujeta enako.
Sedaj, po izvedbi ukaza »datoteka« za datoteko tipa »txt«, smo dobili kodiranje vrste znakov »US-ASCII«. Medtem ko uporablja isto navodilo za datoteke Java in C, kaže, da obe datoteki vsebujeta kodiranje vrste znakov »BINARY«. Poleg tega to navodilo kaže, da so vse te tri datoteke prazne.
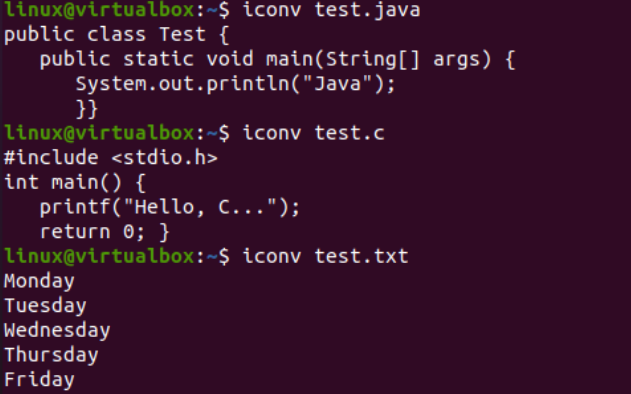
Zdaj bomo ponazorili uporabo ukaza iconv na konzoli za pretvorbo določene kodirne datoteke nabora znakov v drugo kodiranje nabora znakov. Pred tem moramo v naše datoteke dodati kodo ali podatke. Zato smo v datoteko »text.java« dodali kodo Java, v datoteko »text.c« kodo C in v datoteko »test.txt« dodali besedilne podatke. Tukaj je bila uporabljena poizvedba cat za prikaz vsebine vseh treh datotek, kot je predstavljeno spodaj:
Zdaj, ko smo uspešno dodali podatke, bomo znova videli kodiranje nabora znakov teh datotek. Torej smo poskusili isto navodilo za datoteko znotraj lupine z zastavico '-I' in imeni datotek, tj. test.txt, test.java in test.c. Ločeno izvajanje teh treh navodil za vse tri datoteke pokaže, da je bilo kodiranje nabora znakov posodobljeno za datoteke Java in C, medtem ko je ostalo enako za besedilno datoteko, tj. US-ASCII. Kodiranje datotek Java in C je bilo prej »binarno«; zdaj je 'US-ASCII'. Prav tako kaže, da besedilna datoteka vsebuje podatke z navadnim besedilom, medtem ko drugi dve kodni datoteki vsebujeta skripte kot vsebino.

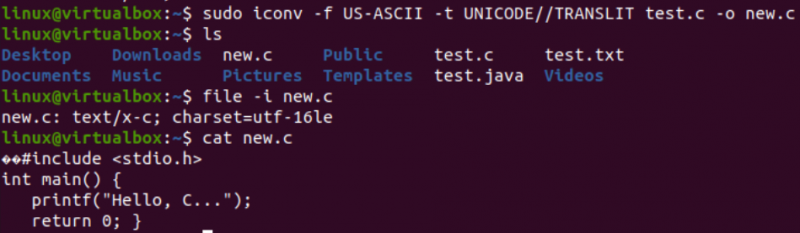
Čas je, da izvedemo dejansko nalogo, potrebno za ta članek, tj. pretvorimo eno kodiranje v drugo z ukazom iconv v lupini. Tako smo uporabljali navodilo 'iconv' znotraj terminala lupine s privilegiji 'sudo'. Ta ukaz uporablja možnost »-f«, ki pomeni »from«, možnost »-t« pa pomeni »to«, tj. od enega kodiranja do drugega.
Za možnostjo »-f« morate določiti kodiranje, ki ga vaša datoteka že ima, tj. US-ASCII. Za možnostjo »-t« morate določiti kodiranje, ki ga želite zamenjati s starim kodiranjem, tj. UNICODE. Ime datoteke, ki se uporablja kot izvor, morate določiti z možnostjo –o, da ustvarite njeno sliko predmeta. Slika predmeta bi bila druga datoteka, tj. »new.c«, iste vrste, vendar z novim kodiranjem in enakimi podatki.
Po izvedbi naslednjega navodila boste dobili novo datoteko v istem imeniku, tj. glede na poizvedbo »ls«. Zdaj bomo preverili kodiranje nabora znakov nove datoteke, ustvarjene z navodilom iconv. Ponovno bomo uporabili navodilo »file« z možnostjo »-I« in novim imenom datoteke, t.j. new.c.
Videli boste, da se je nabor znakov za to novo datoteko razlikoval od nabora znakov stare datoteke, tj. nabora znakov UTF-16LE. To je zato, ker smo kodiranje US-ASCII prevedli v kodiranje UNICODE z uporabo navodil iconv za našo datoteko new.c. Poizvedba »cat« je prikazala isto kodo C v datoteki, vendar se je začela z nekaterimi znaki Unicode, kot je bilo že predstavljeno.
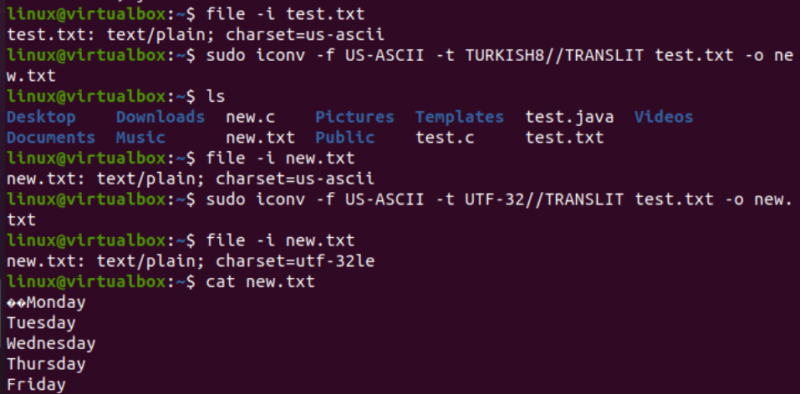
Na zelo podoben način bomo spremenili kodiranje besedilne datoteke test.txt. Navodila za datoteko kažejo, da ima kodiranje nabora znakov US-ASCII. Ukaz iconv je bil uporabljen z enakim formatom za pretvorbo kodiranja datoteke test.txt iz US-ASCII v TURKISH8. Videli boste, da US-ASCII ne spremeni v turščino.
Po tem smo isti ukaz uporabili za pokrivanje kodiranja nabora znakov US-ASCII do UTF-32 za isto datoteko. Tokrat deluje. Včasih lahko pride do težave pri pretvorbi enega nabora kodiranja v drugega ali pa ga drugo kodiranje ne podpira.
Zaključek
Ta članek je razpravljal o tem, kako uporabiti navodila iconv Linux za pretvorbo enega nabora znakov za kodiranje v drugega z uporabo njihovih vzdevkov. Na ta način smo morali ustvariti nekaj datotek različnih vrst.