Ta vodnik bo prikazal postopek uporabe povzetka pogovora v LangChain.
Kako uporabljati povzetek pogovora v LangChainu?
LangChain ponuja knjižnice, kot je ConversationSummaryMemory, ki lahko izvleče celoten povzetek klepeta ali pogovora. Uporablja se lahko za pridobivanje glavnih informacij pogovora, ne da bi morali prebrati vsa sporočila in besedilo, ki je na voljo v klepetu.
Če se želite naučiti postopka uporabe povzetka pogovora v LangChainu, preprosto sledite naslednjim korakom:
1. korak: Namestite module
Najprej namestite ogrodje LangChain, da dobite njegove odvisnosti ali knjižnice z naslednjo kodo:
pip namestite langchain
Zdaj namestite module OpenAI po namestitvi LangChaina z ukazom pip:
pip namestite openai 
Po namestitvi modulov preprosto nastavite okolje z naslednjo kodo po pridobitvi ključa API iz računa OpenAI:
uvoz tiuvoz getpass
ti . približno [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Ključ API OpenAI:' )
2. korak: Uporaba povzetka pogovora
Vstopite v postopek uporabe povzetka pogovora z uvozom knjižnic iz LangChaina:
od Langchain. spomin uvoz ConversationSummaryMemory , ChatMessageHistoryod Langchain. llms uvoz OpenAI
Konfigurirajte pomnilnik modela z metodama ConversationSummaryMemory() in OpenAI() in shranite podatke vanj:
spomin = ConversationSummaryMemory ( llm = OpenAI ( temperaturo = 0 ) )spomin. shrani_kontekst ( { 'vnos' : 'zdravo' } , { 'izhod' : 'zdravo' } )
Zaženite pomnilnik tako, da pokličete load_memory_variables() metoda za ekstrahiranje podatkov iz pomnilnika:
spomin. load_memory_variables ( { } ) 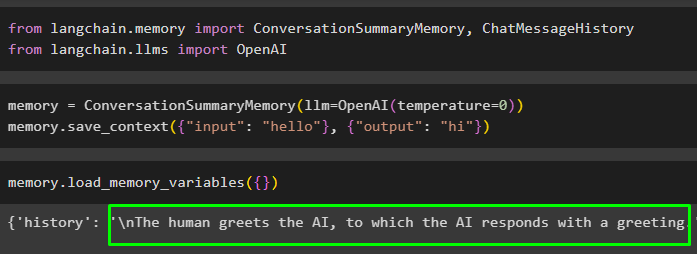
Uporabnik lahko podatke dobi tudi v obliki pogovora, kot vsaka entiteta z ločenim sporočilom:
spomin = ConversationSummaryMemory ( llm = OpenAI ( temperaturo = 0 ) , povratna_sporočila = Prav )spomin. shrani_kontekst ( { 'vnos' : 'zdravo' } , { 'izhod' : 'Živjo kako si' } )
Če želite ločeno prejeti sporočilo AI in ljudi, izvedite metodo load_memory_variables():
spomin. load_memory_variables ( { } ) 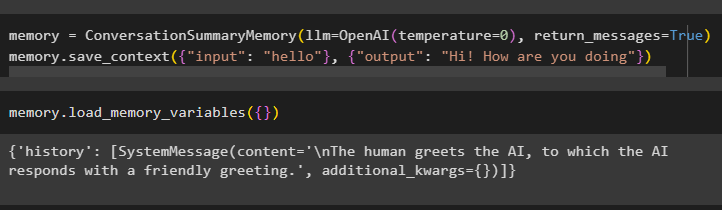
Shranite povzetek pogovora v pomnilnik in nato izvedite pomnilnik, da prikažete povzetek klepeta/pogovora na zaslonu:
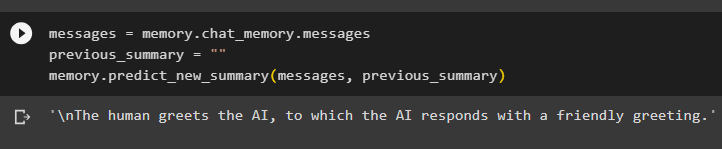
sporočila = spomin. chat_memory . sporočilaprejšnji_povzetek = ''
spomin. napoved_nov_povzetek ( sporočila , prejšnji_povzetek )
3. korak: Uporaba povzetka pogovora z obstoječimi sporočili
Uporabnik lahko dobi tudi povzetek pogovora, ki obstaja zunaj razreda ali klepeta s sporočilom ChatMessageHistory(). Ta sporočila je mogoče dodati v pomnilnik, da lahko samodejno ustvari povzetek celotnega pogovora:
zgodovina = ChatMessageHistory ( )zgodovina. add_user_message ( 'zdravo' )
zgodovina. add_ai_message ( 'Zdravo!' )
Zgradite model, kot je LLM, z uporabo metode OpenAI() za izvajanje obstoječih sporočil v chat_memory spremenljivka:
spomin = ConversationSummaryMemory. iz_sporočil (llm = OpenAI ( temperaturo = 0 ) ,
chat_memory = zgodovina ,
povratna_sporočila = Prav
)
Izvedite pomnilnik z medpomnilnikom, da dobite povzetek obstoječih sporočil:
spomin. medpomnilnik 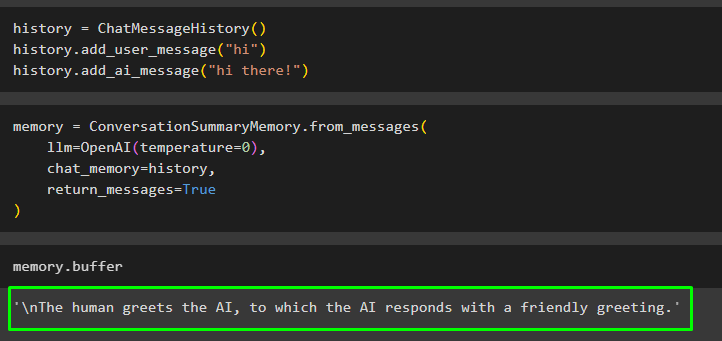
Izvedite naslednjo kodo za izgradnjo LLM s konfiguracijo vmesnega pomnilnika s pomočjo sporočil klepeta:
spomin = ConversationSummaryMemory (llm = OpenAI ( temperaturo = 0 ) ,
medpomnilnik = '''Človek sprašuje stroj o sebi
Sistem odgovarja, da je umetna inteligenca zgrajena za dobro, saj lahko ljudem pomaga doseči njihov potencial''' ,
chat_memory = zgodovina ,
povratna_sporočila = Prav
)
4. korak: Uporaba povzetka pogovora v verigi
Naslednji korak pojasnjuje postopek uporabe povzetka pogovora v verigi z LLM:
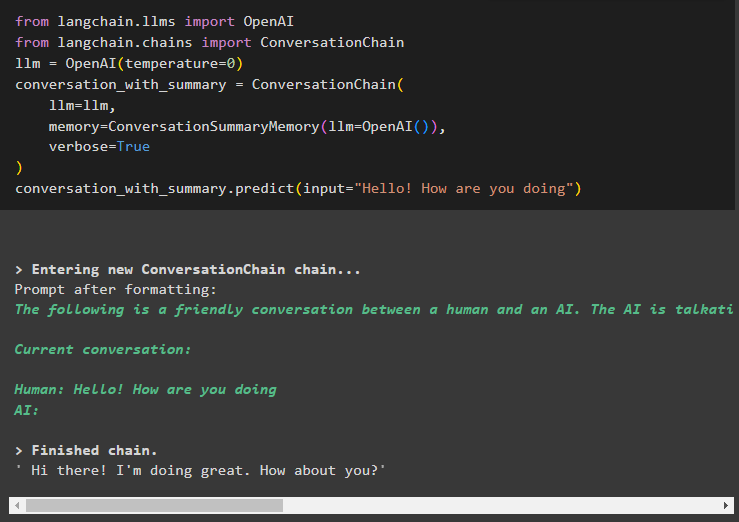
od Langchain. llms uvoz OpenAIod Langchain. verige uvoz ConversationChain
llm = OpenAI ( temperaturo = 0 )
pogovor_s_povzetkom = ConversationChain (
llm = llm ,
spomin = ConversationSummaryMemory ( llm = OpenAI ( ) ) ,
verbose = Prav
)
pogovor_s_povzetkom. napovedati ( vnos = 'Živjo kako gre' )
Tukaj smo začeli graditi verige tako, da smo pogovor začeli z vljudnim povpraševanjem:
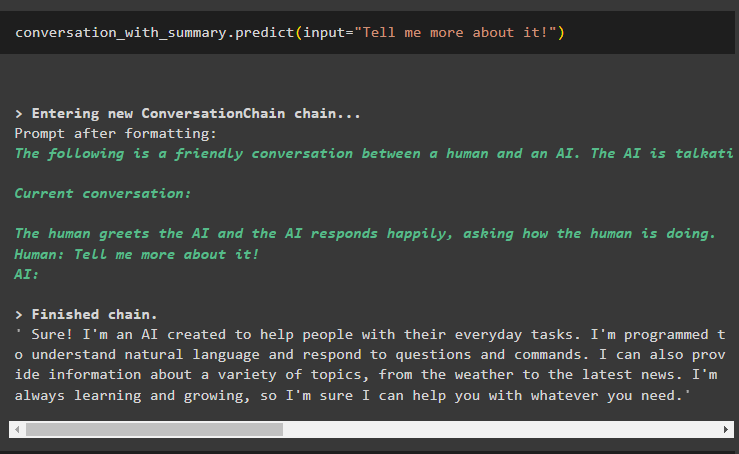
Zdaj se vključite v pogovor tako, da vprašate nekaj več o zadnjem rezultatu, da ga razširite:
pogovor_s_povzetkom. napovedati ( vnos = 'Povej mi več o tem!' )Model je razložil zadnje sporočilo s podrobnim uvodom v tehnologijo AI ali chatbot:
Izvlecite zanimivost iz prejšnjega rezultata, da pogovor usmerite v določeno smer:
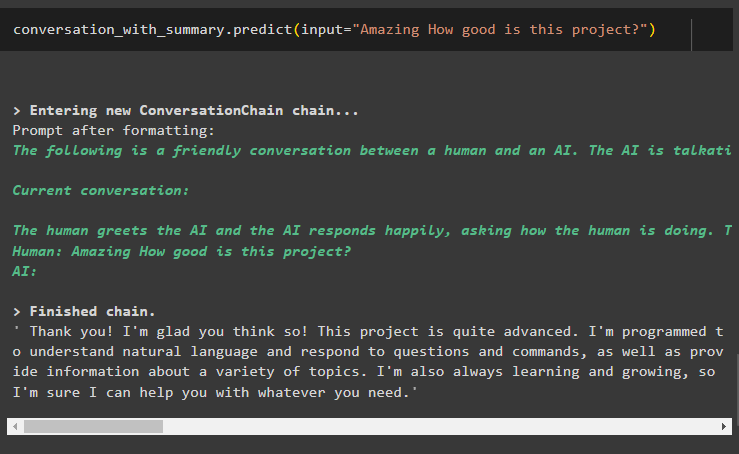
pogovor_s_povzetkom. napovedati ( vnos = 'Neverjetno, kako dober je ta projekt?' )Tukaj dobivamo podrobne odgovore od bota, ki uporablja knjižnico pomnilnika povzetka pogovora:
To je vse o uporabi povzetka pogovora v LangChainu.
Zaključek
Če želite uporabiti sporočilo s povzetkom pogovora v LangChain, preprosto namestite module in okvire, ki so potrebni za nastavitev okolja. Ko je okolje nastavljeno, uvozite ConversationSummaryMemory knjižnico za gradnjo LLM z uporabo metode OpenAI(). Nato preprosto uporabite povzetek pogovora, da iz modelov izvlečete podroben rezultat, ki je povzetek prejšnjega pogovora. Ta priročnik je podrobneje razložil postopek uporabe pomnilnika povzetkov pogovorov z uporabo modula LangChain.