»V »pandah« lahko preprosto preberemo besedilno datoteko s pomočjo metode »pande«. »Pandas« nam ponuja možnost branja besedilne datoteke. »Pandas« nudi različne vgrajene metode za branje besedilne datoteke. V tej vadnici bomo razpravljali o vseh metodah skupaj z vsemi parametri tukaj in jih bomo podrobno razložili. Prav tako bomo prebrali besedilno datoteko v »pandah« z uporabo metod »pand« v naših kodah tukaj.«
Metode za branje besedilne datoteke v »pandah«
V »pandah« imamo tri metode, ki nam pomagajo pri branju besedilne datoteke. Tukaj smo naredili tudi nekaj primerov, v katerih beremo besedilno datoteko. Spodaj so opisane metode, ki jih ponuja »pandas«:
-
- Z uporabo metode pd.read_csv().
- Z uporabo metode pd.read_table().
- Z uporabo metode pd.read_fwf().
V tej vadnici zdaj razlagamo sintakso vseh teh metod in tudi podrobno razpravljamo o parametrih vseh metod.
Sintaksa read_csv()
pd.read_csv ( 'imedatoteke.txt', sep =' ', glava =Brez, imena = [ “Ime_stolpca1”, “Ime_stolpca2, “Ime_stolpca2”, ………….. ] )
Pri tej metodi najprej dodamo ime besedilne datoteke, katere podatke želimo brati, in je prvi parameter te metode. Nato postavimo »sep«, ki je v tej metodi ločilo, in sem postavimo presledek kot znak, tako da bo presledek obravnaval kot ločilo. Po tem imamo parameter glave in uporabljena je vrednost »Brez« tega parametra, tako da bo ustvaril privzeto glavo in če tega parametra ne dodamo, bo upošteval prvo vrstico besedilne datoteke kot glavo. V parameter “names” lahko dodamo imena stolpcev, ki jih moramo dodati kot glavo.
Sintaksa read_table()
pd.read_table ( 'imedatoteke.txt' , ločilo = ' ' )
Pri tej metodi kot prvi parameter postavimo ime besedilne datoteke. Ko v ločilo postavimo » «, bo kot ločilo prevzel presledek.
Sintaksa read_fwf()
pd.read_fwf ( 'imedatoteke.txt' )
Ta metoda sprejme samo en parameter, ki je ime besedilne datoteke.
Zdaj bomo te metode uporabili za branje besedilnih datotek v kodah »pandas« in prikazovanje podatkov besedilne datoteke na terminalu.
Primer št. 01
Tukaj je aplikacija »Spyder«, v kateri smo naredili vse te kode, ki so predstavljene v tej vadnici. Spodaj je prikazana besedilna datoteka, katere podatke želimo prebrati. Uporabili bomo metodo »read_csv()« za branje te besedilne datoteke v »pandah«.
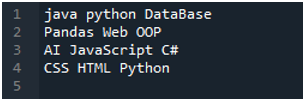
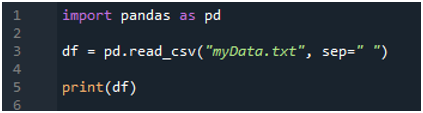
Najprej uvozimo knjižnico »pandas«, ker želimo uporabiti metodo »read_csv()«, to pa je metoda »pandas«. Do te metode dostopamo samo, ko smo uvozili knjižnico »pand«. Tukaj omenjamo 'pande kot pd', zato je ta 'pd' postavljen z imenom metode za njegovo uporabo. Po tem tukaj ustvarimo spremenljivko “df”, ki se uporablja za shranjevanje podatkov besedilne datoteke po branju. Tukaj postavimo metodo »pd.read_csv()«, ki pomaga pri branju besedilne datoteke in pretvorbi podatkov besedilne datoteke v DataFrame ter shranjevanju v spremenljivki »df«.
Tukaj smo posredovali ime datoteke, ki je »myData.txt«, nato pa uporabimo »sep« in temu »sep« dodelimo prazen znak. Torej ta prazen znak deluje kot ločilo v besedilni datoteki. Nato smo spodaj uporabili »print()«, ki se uporablja za tiskanje podatkov besedilne datoteke. Prikazal bo podatke besedilne datoteke v obrazcu DataFrame.
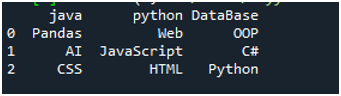
Za izvedbo te kode moramo pritisniti »Shift+Enter« in izhod bo upodobljen na terminalu »Spyder's«. Rezultat zgornje kode je prikazan na danem posnetku zaslona in lahko vidite, da so podatki besedilne datoteke prikazani kot DataFrame, prva vrstica naše besedilne datoteke pa je tukaj predstavljena kot imena stolpcev tega DataFrame. Prav tako loči podatke, kjer je v besedilni datoteki prisoten presledek.
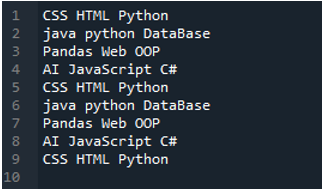
Primer št. 02
Besedilna datoteka, ki jo bomo prebrali v tem primeru, je prikazana tukaj in ponovno bomo uporabili metodo »read_csv()«, vendar z drugačnimi parametri.
Uporabljena je metoda »pandas« »pd.read_csv()« in tukaj posredujemo tri parametre. Najprej postavimo ime datoteke, ki je »Record.txt«. Drugi parameter je parameter »sep« in mu dodeli prazen znak, nato pa imamo tretji parameter, v katerem nastavimo »header« in ga prilagodimo na »None«, tako da bo ustvaril privzeto glavo DataFrame ko izvajamo to kodo. Vse to smo shranili v spremenljivko “My_Record” in dodali tudi “My_Record” v funkciji “print()” za tiskanje.

Vsi podatki so shranjeni v DataFrame in ločuje podatke, kjer je prisoten presledek v podatkih besedilne datoteke. Poleg tega je tukaj ustvaril privzeto glavo DataFrame, ker smo parameter »header« prilagodili na »None«.
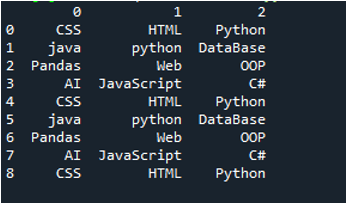
Primer št. 03
Prikaže se besedilna datoteka tega primera in ponovno bomo uporabili metodo »read_csv()« s spremenjenimi parametri.
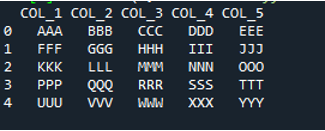
V tej kodi so tukaj posredovani štirje parametri metodi »pande« »pd.read_csv()«. Ime besedilne datoteke je prvi parameter. Parameter »sep« ima v drugem parametru prazen znak. Parameter »header« je v tretjem argumentu nastavljen na »None«, kot četrti parameter pa smo nastavili »names«, ki se bodo pojavila kot imena stolpcev DataFrame po branju besedilne datoteke, ta imena stolpcev pa so “COL_1, COL_2, COL_3, COL_4 in COL_5”. Vse te informacije so bile shranjene v spremenljivki »My_Record«, »My_Record« pa je bil dodan tudi metodi »print()«, tako da se natisne na terminalu.

Vse informacije besedilne datoteke so tukaj upodobljene kot DataFrame, prav tako pa ločuje podatke, kjer so v besedilni datoteki dodani presledki. Ustrezno doda tudi imena stolpcev, ki smo jih dodali zgoraj v kodi.
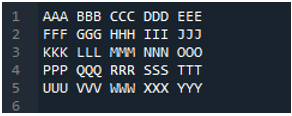
Primer št. 04
To je besedilna datoteka, ki jo bomo prebrali v tem primeru z uporabo druge metode, metode »pd.read_table()«.
Tukaj je dodana metoda »pd.read_table()« za branje besedilne datoteke in dodamo »ABC.txt«, ki je ime besedilne datoteke. Ta metoda pomaga pri branju besedilne datoteke, prav tako pa smo parameter »delimiter« prilagodili presledku, tako da bo deloval tudi kot ločilo, ki smo ga razložili zgoraj. Nato se vsi podatki besedilne datoteke shranijo v spremenljivko »My_Data« in se tukaj tudi natisnejo.

Začetna vrstica naše besedilne datoteke je tukaj prikazana kot imena stolpcev DataFrame, podatki besedilne datoteke pa so natisnjeni kot DataFrame. Poleg tega ločuje podatke besedilne datoteke, kjer je prisoten presledek.
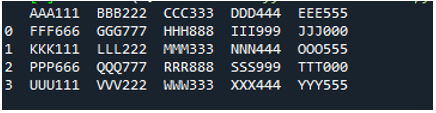
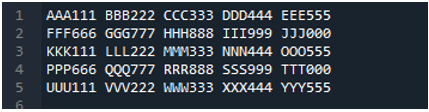
Primer št. 05
Zdaj besedilna datoteka vsebuje podatke, ki so prikazani spodaj. Tokrat bomo uporabili »read_fwf()« in pokazali, kako upodablja podatke po branju besedilne datoteke.
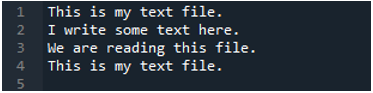
Kot vemo, ta metoda »read_fwf()« sprejme samo en parameter, to je ime datoteke, ki jo želimo prebrati. Tukaj dodamo »textfile.txt«, kar je ime naše besedilne datoteke, in dodelimo to metodo pandas spremenljivki »File_Data«, ki bo shranila podatke te besedilne datoteke. Nato postavimo »print(File_Data)«, tako da natisne tudi te podatke.

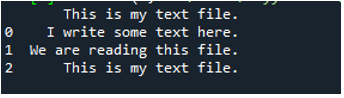
Tukaj so prikazani vsi podatki besedilne datoteke. Ni ločil podatkov, kjer so prisotni presledki, ker v tej funkciji ni parametrov, kot sta »Sep« ali »delimiter«.
Zaključek
Ta vadnica pojasnjuje, kako prebrati besedilno datoteko v »pandah« in katere metode se uporabljajo za branje besedilne datoteke v »pandah«. Razpravljali smo o vseh metodah, ki nam pomagajo pri branju besedilne datoteke v »pandah«. V tej vadnici smo raziskali tri različne metode »pand« za branje naših besedilnih datotek v »pandah«. Tukaj smo tudi podrobno razložili sintakso vseh metod in parametre vseh metod ter prebrali veliko besedilnih datotek z uporabo različnih metod z vsemi možnimi parametri v tej vadnici.