Pande so med najbolj priljubljenimi orodji, ki jih danes uporabljajo podatkovni znanstveniki za analizo tabelarnih podatkov. Za obravnavo tabelarične vsebine ponuja hitrejši in učinkovitejši API. Kadarkoli med analizo gledamo podatkovne okvire, Pandas samodejno nastavi različna vedenja prikaza na privzete vrednosti. Ta vedenja prikaza vključujejo, koliko vrstic in stolpcev je treba prikazati, natančnost lebdečih vrednosti v vsakem podatkovnem okviru, velikosti stolpcev itd. Odvisno od zahtev bomo morda morali občasno spremeniti te privzete nastavitve. Pande imajo različne pristope za spreminjanje privzetega vedenja. Izkoriščanje atributa »možnosti« pand nam je omogočilo spremembo tega vedenja.
Pande prikažejo največje število vrstic
Kadarkoli poskušate natisniti ogromen podatkovni okvir, ki vsebuje več vrstic in stolpcev od vnaprej določenega praga, bo izpis obrezan. Če želite prikazati vse vrstice v DataFrame, se boste v tej vadnici naučili, kako spremeniti možnosti prikaza Panda. Panda privzeto omeji število stolpcev in vrstic, ki jih prikazuje. Čeprav je to lahko uporabno za branje vsebine, pogosto povzroča razočaranje, če informacije, ki si jih želite ogledati, niso prikazane. Tukaj bomo uporabili spodaj navedene metode z njihovo sintakso za prikaz vseh stolpcev podatkovnega okvira.
to_string()

set_option()

option_context()

Naučili se bomo uporabe vseh teh metod s praktično implementacijo za prikaz največjega števila vrstic v ponujenem podatkovnem okviru.
Primer # 1: Uporaba metode Pandas to_string().
Ta predstavitev nas bo naučila prikazati največje število vrstic v podatkovnem okviru na terminalu z uporabo pandasove metode »to_string()«.
Za prevajanje in izvajanje vzorčnih programov smo izbrali orodje »Spyder«. V tem priročniku bomo to orodje uporabili za izvedbo vseh naših primerov. Zagnali smo orodje »Spyder« za začetek pisanja skripta python. Začenši s kodo, moramo najprej naložiti potrebne knjižnice v našo datoteko python, da nam bo dovoljeno uporabljati njene funkcije. Knjižnica modulov, ki jo tukaj potrebujemo, je »Pandas«. Torej, uvozili smo ga v našo datoteko python in ga poimenovali »pd«.
Ker je glavna operacija tega članka prikaz največjega števila vrstic podatkovnega okvira, najprej potrebujemo podatkovni okvir. Zdaj je odvisno od vas, ali boste raje ustvarili podatkovni okvir ali uvozili datoteko CSV. Uvozili smo vzorčno datoteko CSV. Za branje datoteke CSV v program python smo uporabili funkcijo pande »pd.read_csv()«. Med oklepaji te funkcije smo navedli datoteko CSV, za katero želimo prebrati zaslon, ki je »industry.csv«. Konstruirali smo spremenljivko 'df' za shranjevanje izhoda, ustvarjenega z branjem predložene datoteke CSV. Nato smo priklicali metodo »print()« za prikaz podatkovnega okvira.
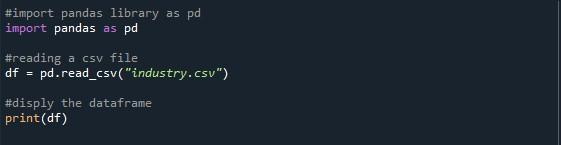
Ko zaženemo ta program python s pritiskom na možnost »Zaženi datoteko«, se na konzoli prikaže podatkovni okvir. Opazite lahko, da je v spodnjem rezultatu 43 vrstic, prikazanih pa je le deset. To je zato, ker je privzeta vrednost knjižnice Pandas le 10 vrstic.
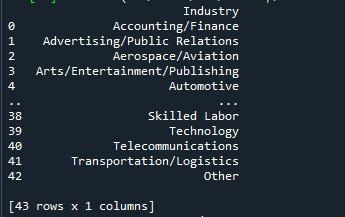
Za prikaz vseh vrstic tukaj bomo uporabili metodo pande »to_string«. Najbolj enostaven način za prikaz največjega števila vrstic iz podatkovnega okvira je ta tehnika. Ker pa spremeni celoten okvir podatkov v en sam niz, ni priporočljiv za zelo velike nize podatkov (v milijonih). Kljub temu to učinkovito deluje za nize podatkov, ki so dolgi na tisoče.
Sledili smo zgornji sintaksi za funkcijo »to_string()«. Preprosto smo priklicali metodo »to_string()« z imenom našega podatkovnega okvira. Nato smo to metodo umestili v funkcijo »print()«, da jo prikažemo ob klicu.

Izhodni posnetek nam pokaže podatkovni okvir z vsemi vrsticami, ki so prikazane na terminalu.
Primer # 2: Uporaba metode Pandas set_option
Druga metoda, ki jo bomo izvajali v tem priročniku, je pandas »set_option()« za prikaz največjega števila vrstic podanega podatkovnega okvira.
V datoteko python smo uvozili knjižnico pandas za dostop do zgoraj omenjene funkcije. Za branje predložene datoteke CSV smo uporabili pande »pd.read_csv()«. Priklicali smo funkcijo »pd.read_CSV()« z imenom datoteke CSV, ki jo želimo uporabiti med njenimi oklepaji in je »Sampledata.csv«. Ko uvažate datoteko CSV, imejte v mislih trenutni delovni imenik programa Python. Vaša datoteka CSV mora biti nameščena v istem imeniku; sicer boste prejeli sporočilo o napaki »datoteke ni mogoče najti«. Ustvarili smo spremenljivko »vzorec« za shranjevanje podatkovnega okvira iz datoteke CSV. Za prikaz tega podatkovnega okvira smo poklicali metodo »print()«.
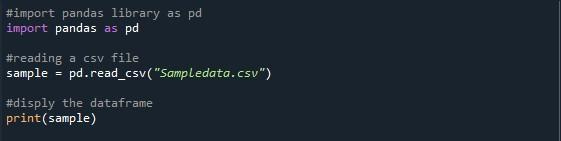
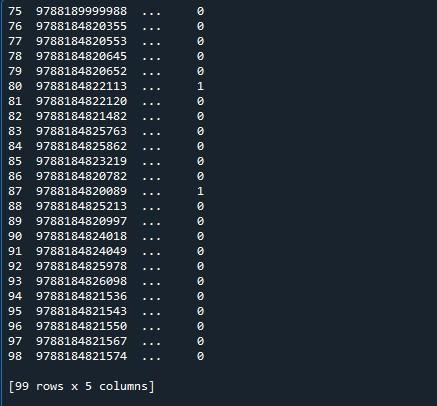
Tukaj imamo naš rezultat, kjer je prikazanih samo deset vrstic. Največje navedeno število vrstic je 99. Vse druge vrstice med prvimi 5 in zadnjimi petimi vrsticami so odrezane.

Za prikaz največjega števila vrstic, ki so 99 za ta podatkovni okvir, bomo uporabili funkcijo »set_option()« modula pandas. Pande imajo operacijski sistem, ki omogoča spreminjanje vedenja in prikaza. Ta metoda nam omogoča, da zaslon nastavimo tako, da prikazuje celoten podatkovni okvir namesto okrnjenega. Pande ponujajo funkcijo »set_ option()« za prikaz vseh vrstic podatkovnega okvira.
Poklicali smo “pd.set_option()”. Ta funkcija ima parametre “display.max_rows”. “display.max_rows” določa največje število vrstic, ki bodo prikazane pri prikazu podatkovnega okvira. Vrednost »max_rows« je privzeto nastavljena na 10. Če je izbrano »Brez«, to označuje vse vrstice v podatkovnem okviru. Ker želimo prikazati vse vrstice, ga nastavimo na »Brez«. Nazadnje smo uporabili funkcijo »print()« za prikaz podatkovnega okvira z največ vrsticami.

To prinese rezultat, prikazan na spodnjem posnetku.
Primer # 3: Uporaba metode Pandas option_context().
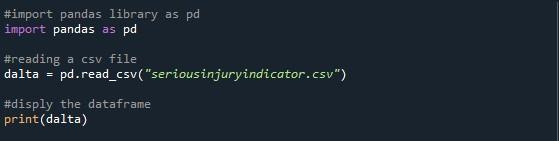
Zadnja metoda, o kateri razpravljamo tukaj, je »option_context()« za prikaz vseh vrstic podatkovnega okvira. Za to smo uvozili paket pandas v datoteko python in začeli pisati kodo. Za branje datoteke CSV, ki smo jo določili, smo uporabili funkcijo »pd.read_csv()«. Ustvarili smo spremenljivko »dalta« za shranjevanje podatkovnega okvira iz določene datoteke CSV. Nato smo preprosto natisnili podatkovni okvir z metodo »print()«.
Rezultat, ki smo ga dobili z izvajanjem zgornje kode, nam pokaže podatkovni okvir z okrnjenimi vrsticami.
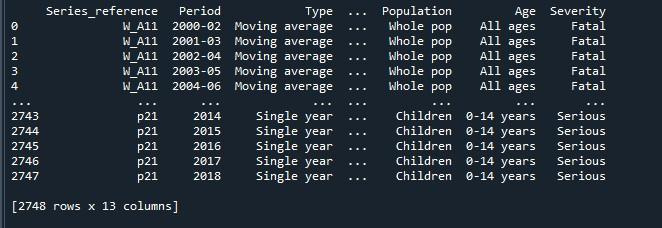
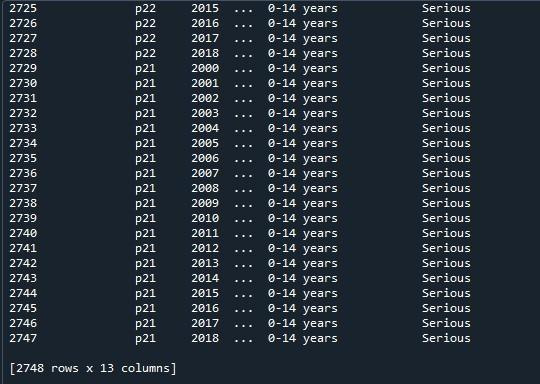
Zdaj bomo na ta podatkovni okvir uporabili pande »pd.option_context()«. Ta funkcija je enaka 'set_option()'. Edina razlika med obema pristopoma je v tem, da »set_option()« trajno spremeni nastavitve, medtem ko jih »option _context()« samo spremeni v svojem obsegu. Ta metoda vzame tudi vrstice display.max kot parameter, ki smo ga nastavili na »Brez« za upodobitev vseh vrstic podatkovnega okvira. Po priklicu te funkcije smo jo samo prikazali z metodo »print()«.

Tukaj si lahko ogledamo celoten podatkovni okvir z največjim številom vrstic, ki jih je 2747.
Zaključek
Ta članek se osredotoča na možnosti prikaza pand. Včasih si bomo morda morali ogledati celoten podatkovni okvir na terminalu. Pande nam ponujajo različne možnosti za ta namen. V tem priročniku smo uporabili tri od teh strategij. Prvi primer je temeljil na uporabi metode »to_string()«. Naš drugi primerek nas uči implementacije »set_option()«, medtem ko zadnja ilustracija izvaja metodo »option_context()«. Vse te tehnike so prikazane, da bi se seznanili z alternativnimi načini, s katerimi nam pande omogočajo doseganje zahtevanega rezultata.