»Vrednosti, ločene z vejicami (CSV) so eden najbolj vsestranskih in za uporabo preprostih formatov podatkov. Je lahek podatkovni format, ki razvijalcem in aplikacijam omogoča prenos in razčlenjevanje podatkov iz enega vira v drugega.
Podatki CSV shranjujejo podatke v obliki tabele, kjer je vsak stolpec ločen z vejico, nov zapis pa je dodeljen novi vrstici. Zaradi tega je zelo dobra izbira za izvoz baz podatkov, kot so baze podatkov SQL, podatki Cassandra in drugo.
Zato ne preseneča, da boste naleteli na scenarij, ko boste morali uvoziti datoteko CSV v svojo bazo podatkov.
Cilj te vadnice je pokazati hitro in preprosto metodo uvoza datoteke CSV v vašo gručo Elasticsearch z uporabo nadzorne plošče Kibana.”
Skočimo noter.
Zahteve
Pred potopom se prepričajte, da izpolnjujete naslednje zahteve:
- Gruča Elasticsearch z zelenim zdravstvenim stanjem.
- Strežnik Kibana, povezan z vašo gručo Elasticsearch.
- Zadostna dovoljenja za upravljanje indeksov v vaši gruči.
Vzorčna datoteka CSV
Kot običajno je prva zahteva izvorna datoteka CSV. Dobro je zagotoviti, da so podatki v datoteki CSV dobro oblikovani in da ne vsebujejo napak.
Za ponazoritev bomo uporabili brezplačen nabor podatkov, ki vsebuje filme in TV-oddaje iz Amazon Prime.
Odprite brskalnik in se pomaknite do spodnjega vira:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Sledite postopku za prenos nabora podatkov na vaš lokalni računalnik. Preneseni arhiv lahko izvlečete z ukazom:
$ razpakirati a~ / Prenosi / arhiv.zip
Uvozi datoteko CSV
Ko imate pripravljeno izvorno datoteko, lahko nadaljujemo in se pogovorimo o tem, kako jo uvoziti.
Začnite tako, da se pomaknete na domačo nadzorno ploščo Kibana in izberete možnost »naloži datoteko«.
V oknu zaganjalnika poiščite ciljno datoteko CSV, ki jo želite uvoziti.
Izberite izvorno datoteko in kliknite naloži.
Dovolite, da Elasticsearch in Kibana analizirata naloženo datoteko. To bo razčlenilo datoteko CSV in določilo format podatkov, polja, tipe podatkov itd.
OPOMBA: Ta postopek lahko traja nekaj časa, odvisno od konfiguracije vaše gruče in velikosti podatkov. Zagotovite, da se glavno vozlišče odziva, da preprečite časovne omejitve.
Ko je postopek končan, bi morali dobiti vzorec vsebine datoteke in statistiko datoteke, kot jo analizira Elastic.
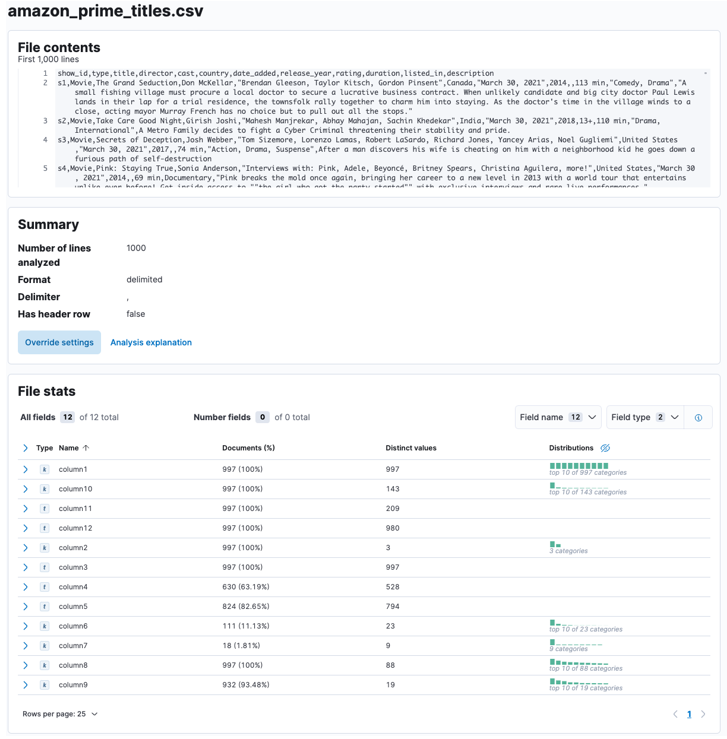
Prilagodite lahko številne parametre, na primer ločilo, vrstice glave itd. Na primer, zgornji izhod lahko prilagodimo tako, da Elastic obvestimo, da naša datoteka CSV vsebuje datoteke glave.
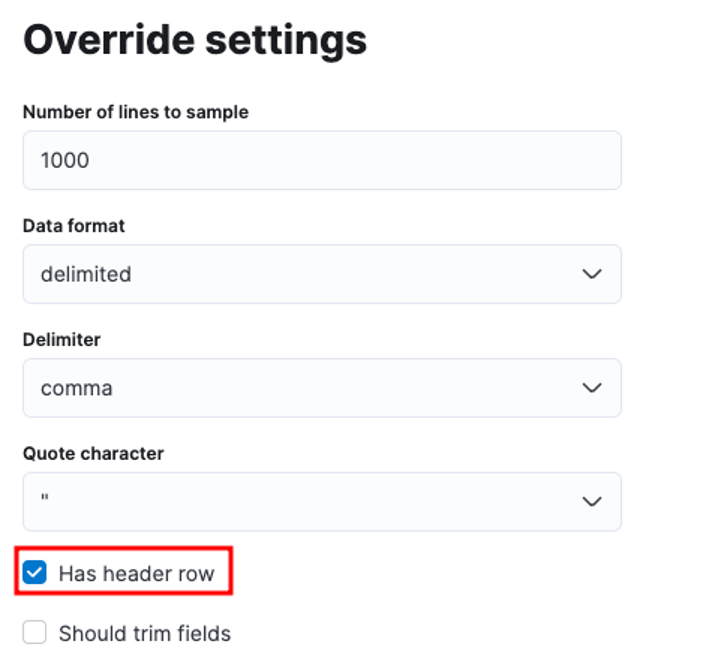
Nato lahko kliknemo Uporabi in ponovno analiziramo podatke. To bi moralo formatirati podatke v pravilni obliki, vključno s polji.
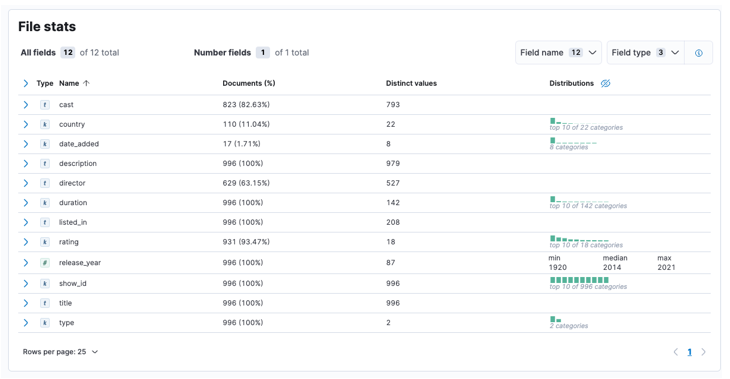
Nato lahko kliknemo uvoz, da nadaljujemo na uvoženo nadzorno ploščo.
Tu moramo ustvariti indeks, v katerem so shranjeni podatki CSV. Svojemu indeksu lahko dodelite katero koli podprto ime.
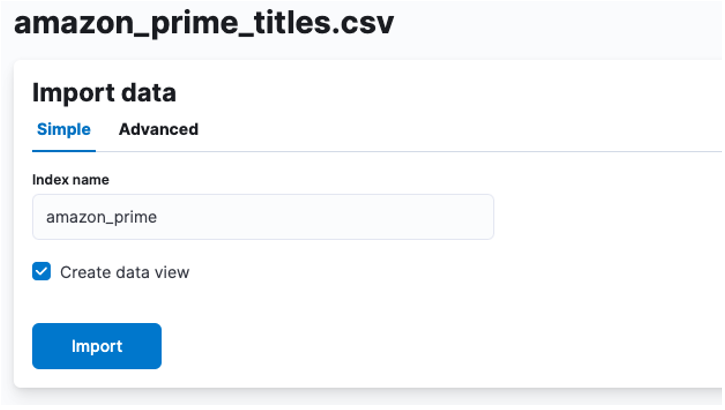
Če želite prilagoditi svoje lastnosti indeksa, kot je število drobcev, replik, preslikav itd. Izberite napredno možnost in prilagodite svoje nastavitve po svojih željah.
Na koncu kliknite uvoz in opazujte, kako Kibana izvaja svojo 'čarovnijo'. Ko končate, lahko do svojega indeksa dostopate prek API-ja Elasticsearch ali uporabite nadzorno ploščo Kibana.
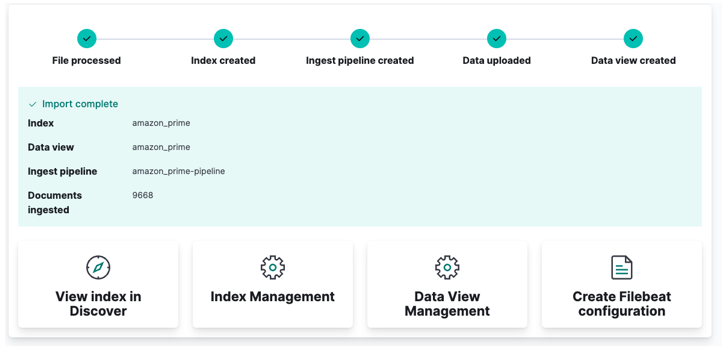
In končali ste!!
Zaključek
V tej objavi smo opisali postopek pridobivanja in uvoza vašega nabora podatkov CSV v vašo gručo Elasticsearch z uporabo nadzorne plošče Kibana.
Hvala za branje in veselo kodiranje!!