V tem priročniku je razloženo, kako ustvariti pajke za pridobivanje podatkov iz vedra S3.
Kako ustvariti pajka za pridobivanje podatkov iz vedra S3?
Če želite ustvariti pajka v AWS, obiščite » Lepilo AWS ” na nadzorni plošči Amazon:
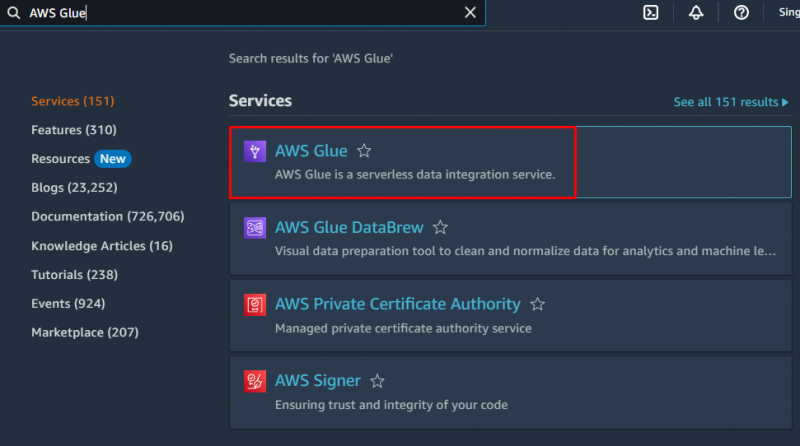
Kliknite na ' Baze podatkov ” v razdelku Katalog podatkov, da ustvarite bazo podatkov:
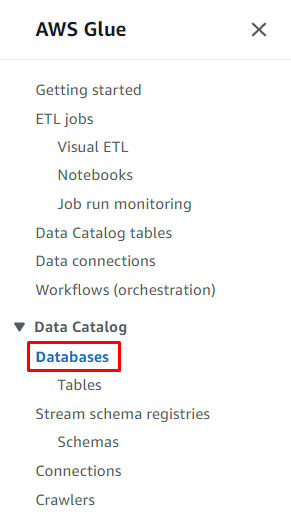
Kliknite na ' Dodajte bazo podatkov ” za začetek konfiguracije:
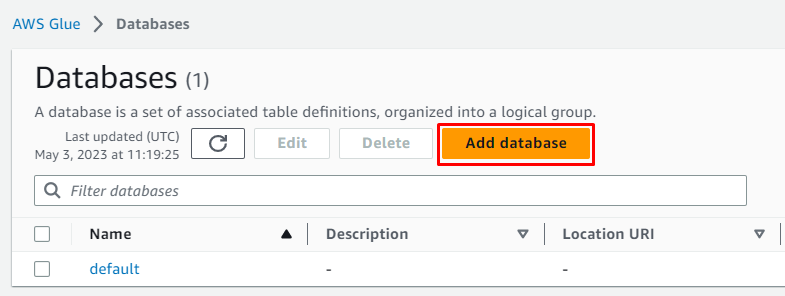
Vnesite ime baze podatkov in pustite vse kot ni obvezno, preden kliknete » Ustvari bazo podatkov ” gumb:
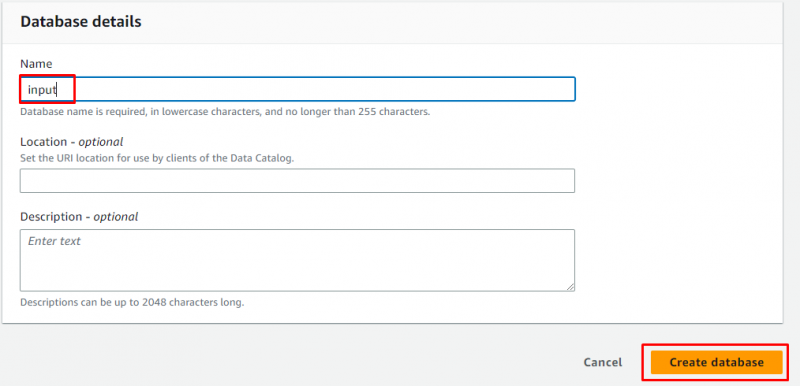
Baza podatkov je bila uspešno ustvarjena:
Po tem preprosto pojdite na » Pajki ”, tako da jo kliknete na levi plošči:
Kliknite na ' Ustvari pajka ” gumb:

Vnesite ime pajka in kliknite » Naslednji ” gumb:

Kliknite na ' Dodajte vir podatkov ” za izbiro vira podatkov:
Če želite preveriti pot, kjer so shranjeni podatki, obiščite storitev S3:
Pojdite v vedro S3, kjer se naložijo podatki. Uporabnik lahko ustvariti vedro in nalaganje podatki o njem z nadzorne plošče AWS S3:

Kliknite na ' Brskajte po S3 ” za izbiro poti podatkov:
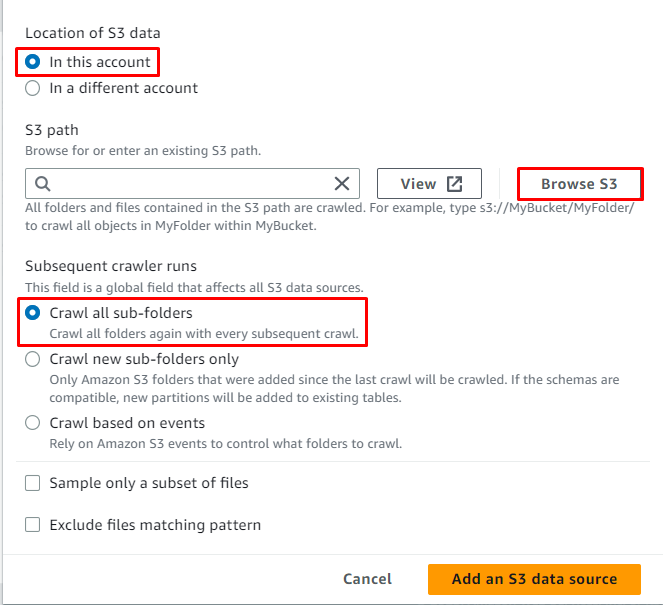
Izberite mapo s podatki in kliknite » Izberite ” gumb:

Pot S3 je bila izbrana, zdaj kliknite » Dodajte vir podatkov S3 ” gumb:

Ko je vir podatkov dodan, preprosto kliknite » Naslednji ” gumb:
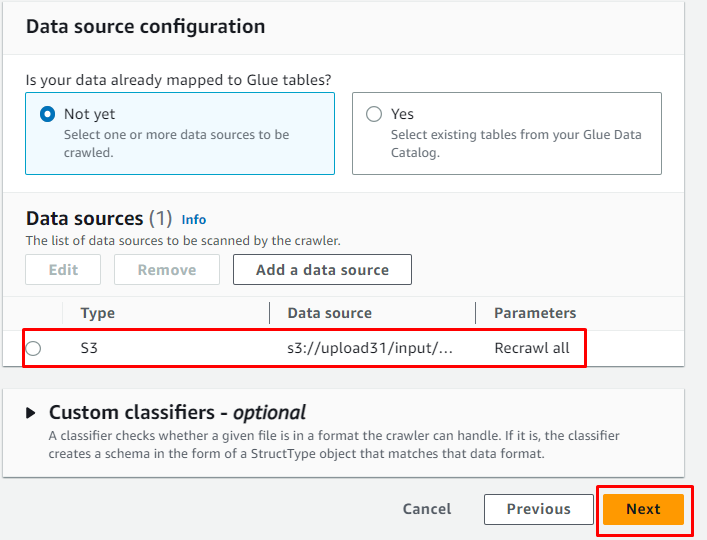
Dodajte vlogo IAM in nato kliknite » Naslednji ” gumb:
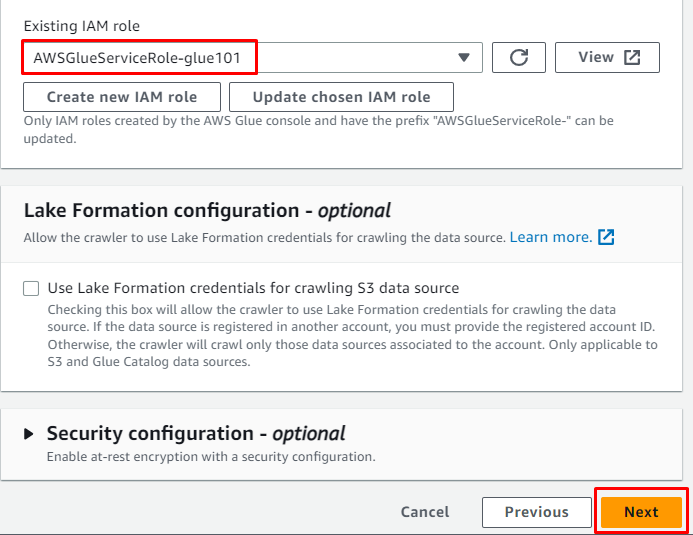
Vnesite prej ustvarjeno ciljno bazo podatkov in nato vnesite ime tabele:
Izberite urnik na zahtevo za pajka in kliknite » Naslednji ” gumb:
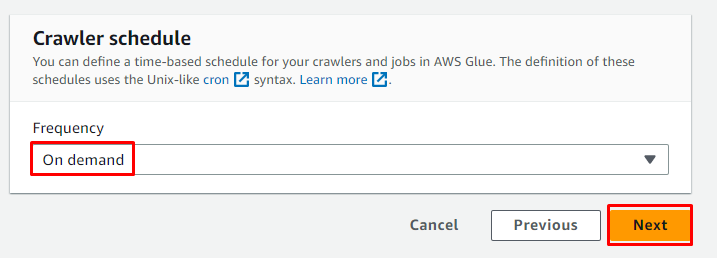
Preglejte pajka in kliknite » Ustvari pajka ” gumb:
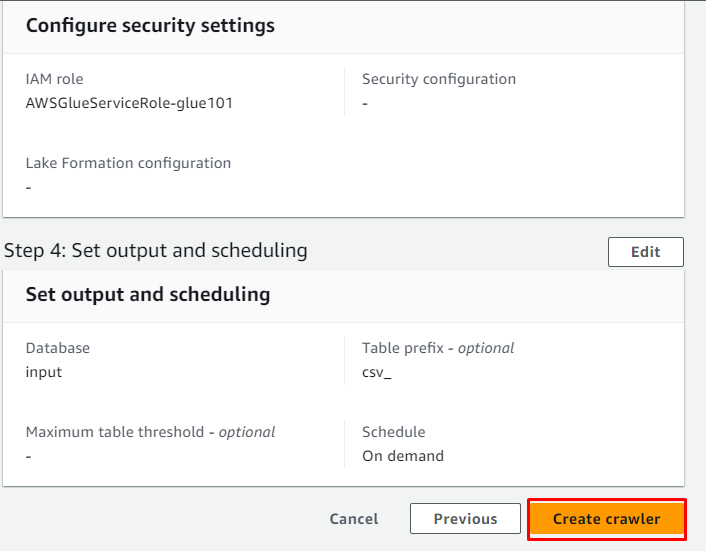
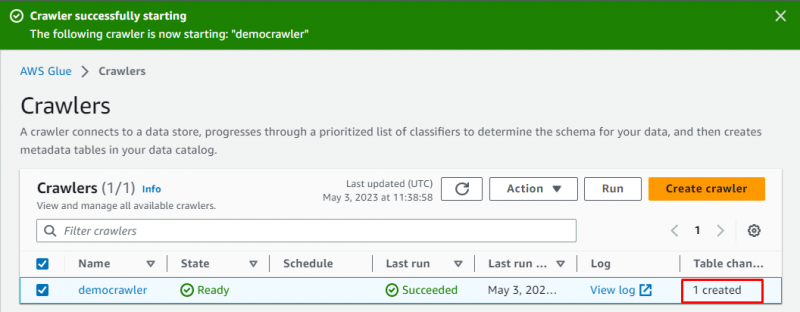
Pajek je bil uspešno ustvarjen, kliknite » Teči ” po izbiri:

Trajalo bo nekaj trenutkov, da se pajek zažene in pridobi podatke ter ustvari tabelo za shranjevanje podatkov:
Pojdite v ' Mize ” na nadzorni plošči Glue:
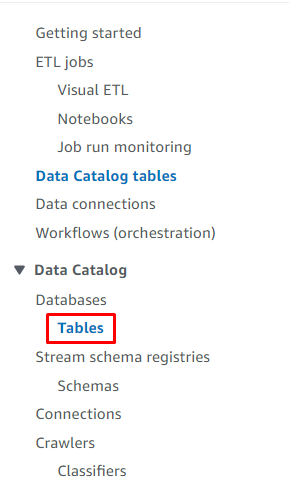
Izberite tabelo s klikom na njeno ime:
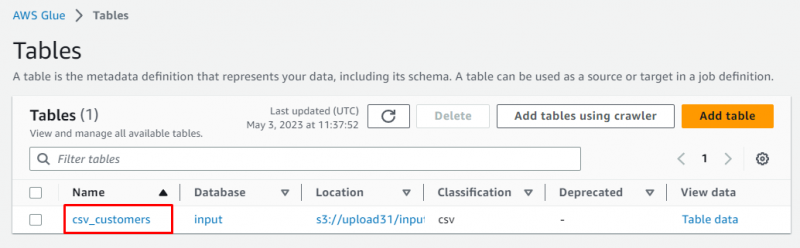
Prikazane so bile podrobnosti zgodbe, ki vsebujejo metapodatke pridobljenih podatkov:
Pomaknite se navzdol po strani in izberite razdelek za ogled tabele s podatki:
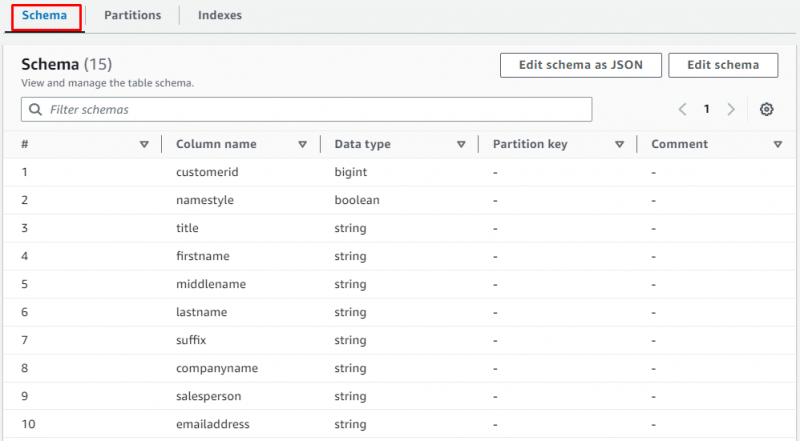
To je vse o ustvarjanju pajka za pridobivanje podatkov iz vedra S3.
Zaključek
Če želite ustvariti pajka za pridobivanje podatkov iz vedra S3, ustvarite bazo podatkov na AWS Glue, v kateri bodo shranjeni pajkani podatki. Konfigurirajte pajka na nadzorni plošči Glue tako, da zagotovite vir podatkov (vedro S3) in ciljno bazo podatkov. Zaženite pajka in pridobite podatke iz vedra S3 v tabelo baze podatkov, kot je podrobno razloženo v tem priročniku.