Ta priročnik bo prikazal, kako uporabljati VectorStoreRetrieverMemory z uporabo ogrodja LangChain.
Kako uporabljati VectorStoreRetrieverMemory v LangChain?
VectorStoreRetrieverMemory je knjižnica LangChain, ki se lahko uporablja za pridobivanje informacij/podatkov iz pomnilnika z uporabo vektorskih shramb. Vektorske shrambe je mogoče uporabiti za shranjevanje in upravljanje podatkov za učinkovito pridobivanje informacij glede na poziv ali poizvedbo.
Če se želite naučiti postopka uporabe VectorStoreRetrieverMemory v LangChain, preprosto preberite ta vodnik:
1. korak: Namestite module
Zaženite postopek uporabe pripomočka za pridobivanje pomnilnika z namestitvijo LangChaina z ukazom pip:
pip namestite langchain
Namestite module FAISS, da dobite podatke z iskanjem semantične podobnosti:
pip namestite faiss-gpu 
Namestite modul chromadb za uporabo podatkovne baze Chroma. Deluje kot vektorska shramba za ustvarjanje pomnilnika za prinašalec:
pip namestite chromadb 
Za namestitev je potreben še en modul tiktoken, ki ga je mogoče uporabiti za ustvarjanje žetonov s pretvorbo podatkov v manjše dele:
pip namestite tiktoken 
Namestite modul OpenAI, če želite uporabljati njegove knjižnice za gradnjo LLM-jev ali chatbotov v njegovem okolju:
pip namestite openai 
Nastavite okolje v Python IDE ali prenosnem računalniku z uporabo ključa API iz računa OpenAI:
uvoz tiuvoz getpass
ti . približno [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Ključ API OpenAI:' )
2. korak: uvozite knjižnice
Naslednji korak je pridobivanje knjižnic iz teh modulov za uporabo prenosnika pomnilnika v LangChain:
od Langchain. pozive uvoz PromptTemplateod Datum čas uvoz Datum čas
od Langchain. llms uvoz OpenAI
od Langchain. vdelave . openai uvoz OpenAIEmbeddings
od Langchain. verige uvoz ConversationChain
od Langchain. spomin uvoz VectorStoreRetrieverMemory
3. korak: Inicializacija vektorske shrambe
Ta priročnik uporablja podatkovno bazo Chroma po uvozu knjižnice FAISS za ekstrahiranje podatkov z vnosnim ukazom:
uvoz faissod Langchain. docstore uvoz InMemoryDocstore
#importing knjižnice za konfiguracijo baz podatkov ali vektorskih shramb
od Langchain. vektorske trgovine uvoz FAISS
#ustvari vdelave in besedila, da jih shraniš v vektorskih trgovinah
velikost_vdelave = 1536
kazalo = faiss. IndexFlatL2 ( velikost_vdelave )
embedding_fn = OpenAIEmbeddings ( ) . embed_query
vectorstore = FAISS ( embedding_fn , kazalo , InMemoryDocstore ( { } ) , { } )
4. korak: Izdelava Retrieverja, ki ga podpira Vector Store
Zgradite pomnilnik za shranjevanje najnovejših sporočil v pogovoru in pridobite kontekst klepeta:
prinašalec = vectorstore. kot_prinašalec ( search_kwargs = dikt ( k = 1 ) )spomin = VectorStoreRetrieverMemory ( prinašalec = prinašalec )
spomin. shrani_kontekst ( { 'vnos' : 'Rad jem pico' } , { 'izhod' : 'fantastično' } )
spomin. shrani_kontekst ( { 'vnos' : 'Dober sem v nogometu' } , { 'izhod' : 'v redu' } )
spomin. shrani_kontekst ( { 'vnos' : 'Ne maram politike' } , { 'izhod' : 'seveda' } )
Preizkusite pomnilnik modela z vnosom, ki ga zagotovi uporabnik z njegovo zgodovino:
tiskanje ( spomin. load_memory_variables ( { 'poziv' : 'kateri šport naj gledam?' } ) [ 'zgodovina' ] ) 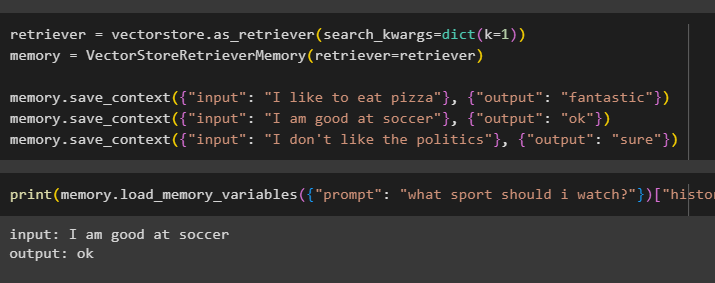
5. korak: Uporaba Retrieverja v verigi
Naslednji korak je uporaba prenosnika pomnilnika z verigami z izgradnjo LLM z uporabo metode OpenAI() in konfiguriranjem predloge poziva:
llm = OpenAI ( temperaturo = 0 )_DEFAULT_TEMPLATE = '''Je interakcija med človekom in strojem
Sistem ustvari koristne informacije s podrobnostmi z uporabo konteksta
Če sistem nima odgovora za vas, preprosto reče, da nimam odgovora
Pomembne informacije iz pogovora:
{zgodovina}
(če besedilo ni relevantno, ga ne uporabljajte)
Trenutni klepet:
Človek: {input}
AI:'''
POZIV = PromptTemplate (
vhodne_spremenljivke = [ 'zgodovina' , 'vnos' ] , predlogo = _DEFAULT_TEMPLATE
)
#konfigurirajte ConversationChain() z uporabo vrednosti za njegove parametre
pogovor_s_povzetkom = ConversationChain (
llm = llm ,
poziv = POZIV ,
spomin = spomin ,
verbose = Prav
)
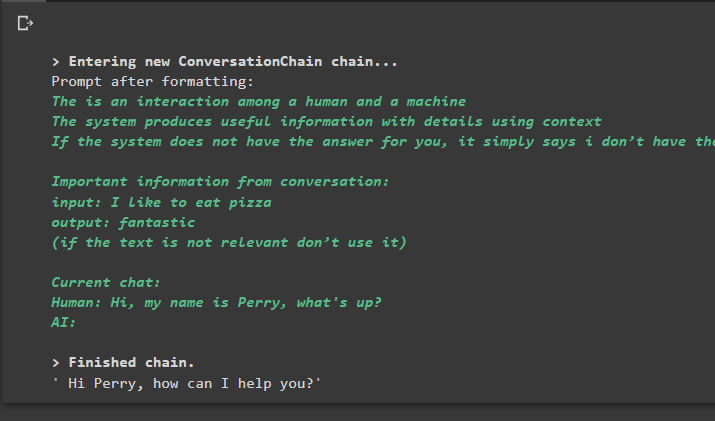
pogovor_s_povzetkom. napovedati ( vnos = 'Živjo, ime mi je Perry, kaj dogaja?' )
Izhod
Izvedba ukaza zažene verigo in prikaže odgovor, ki ga nudi model ali LLM:
Nadaljujte s pogovorom z uporabo poziva na podlagi podatkov, shranjenih v vektorski shrambi:
pogovor_s_povzetkom. napovedati ( vnos = 'kateri je moj najljubši šport?' ) 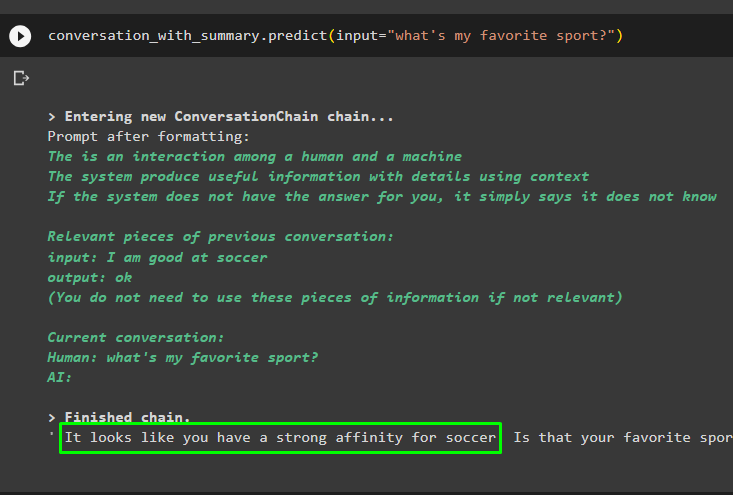
Prejšnja sporočila so shranjena v pomnilniku modela, ki ga lahko model uporabi za razumevanje konteksta sporočila:
pogovor_s_povzetkom. napovedati ( vnos = 'Katera je moja najljubša hrana' ) 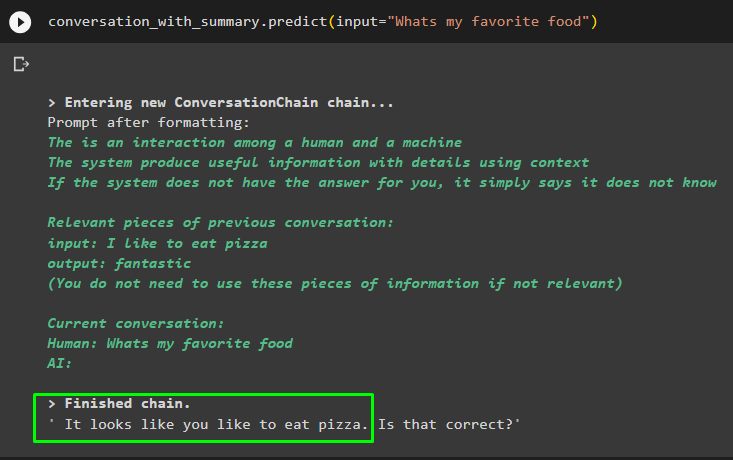
Pridobite odgovor za model v enem od prejšnjih sporočil, da preverite, kako prenosnik pomnilnika deluje z modelom klepeta:
pogovor_s_povzetkom. napovedati ( vnos = 'Kaj je moje ime?' )Model je pravilno prikazal rezultat z iskanjem podobnosti iz podatkov, shranjenih v pomnilniku:
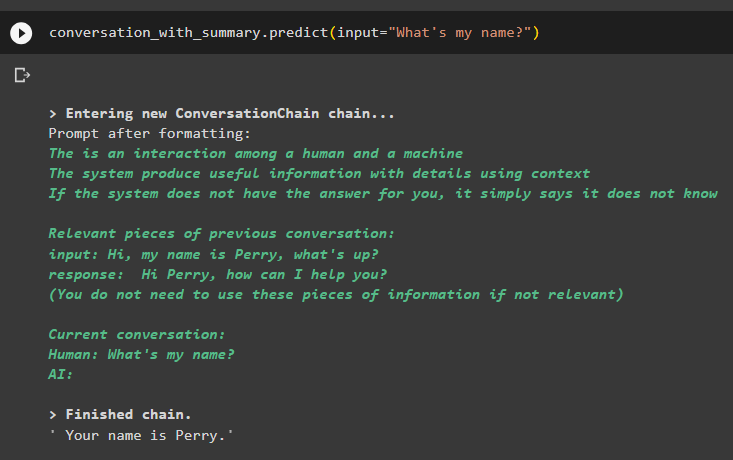
To je vse o uporabi vektorskega retrieverja v LangChainu.
Zaključek
Za uporabo prenosnika pomnilnika, ki temelji na vektorski shrambi v LangChain, preprosto namestite module in ogrodja ter nastavite okolje. Nato uvozite knjižnice iz modulov, da zgradite zbirko podatkov z uporabo Chroma in nato nastavite predlogo poziva. Po shranjevanju podatkov v pomnilnik preizkusite prinašalnik tako, da začnete pogovor in postavljate vprašanja v zvezi s prejšnjimi sporočili. Ta priročnik podrobneje opisuje postopek uporabe knjižnice VectorStoreRetrieverMemory v LangChain.