Hitri oris
Ta objava vsebuje naslednje razdelke:
- Kako uporabljati agenta Async API v LangChain
- 1. način: Uporaba serijskega izvajanja
- 2. način: Uporaba sočasnega izvajanja
- Zaključek
Kako uporabljati agenta Async API v LangChainu?
Modeli klepeta opravljajo več nalog hkrati, kot je razumevanje strukture poziva, njegove zapletenosti, pridobivanje informacij in še veliko več. Uporaba agenta Async API v LangChainu omogoča uporabniku, da zgradi učinkovite modele klepeta, ki lahko odgovorijo na več vprašanj hkrati. Če se želite naučiti postopka uporabe agenta Async API v LangChainu, preprosto sledite tem vodnikom:
1. korak: Namestitev ogrodij
Najprej namestite ogrodje LangChain, da dobite njegove odvisnosti od upravitelja paketov Python:
pip namestite langchain
Po tem namestite modul OpenAI, da zgradite jezikovni model, kot je llm, in nastavite njegovo okolje:
pip namestite openai
2. korak: okolje OpenAI
Naslednji korak po namestitvi modulov je postavitev okolja z uporabo ključa API OpenAI in Serper API za iskanje podatkov iz Googla:
uvoz ti
uvoz getpass
ti . približno [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Ključ API OpenAI:' )
ti . približno [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Serper API Key:' )
3. korak: Uvoz knjižnic
Zdaj, ko je okolje nastavljeno, preprosto uvozite zahtevane knjižnice, kot je asyncio in druge knjižnice z uporabo odvisnosti LangChain:
od Langchain. zastopniki uvoz inicializiraj_agent , load_toolsuvoz čas
uvoz asyncio
od Langchain. zastopniki uvoz AgentType
od Langchain. llms uvoz OpenAI
od Langchain. povratni klici . stdout uvoz StdOutCallbackHandler
od Langchain. povratni klici . sledilci uvoz LangChainTracer
od aiohttp uvoz ClientSession
4. korak: Vprašanja za nastavitev
Nastavite nabor podatkov o vprašanjih, ki vsebuje več poizvedb, povezanih z različnimi domenami ali temami, ki jih je mogoče iskati v internetu (Google):
vprašanja = ['Kdo je zmagovalec odprtega prvenstva ZDA leta 2021' ,
'Koliko je star fant Olivie Wilde' ,
'Kdo je zmagovalec naslova svetovnega prvaka v formuli 1' ,
'Kdo je zmagal v finalu OP ZDA za ženske leta 2021' ,
'Kdo je Beyoncein mož in koliko je star' ,
]
1. način: Uporaba serijskega izvajanja
Ko so vsi koraki končani, preprosto izvedite vprašanja, da dobite vse odgovore z uporabo serijskega izvajanja. To pomeni, da bo naenkrat izvedeno/prikazano eno vprašanje in vrnjen celoten čas, ki je potreben za izvedbo teh vprašanj:
llm = OpenAI ( temperatura = 0 )orodja = load_tools ( [ 'google-header' , 'llm-matematika' ] , llm = llm )
agent = inicializiraj_agent (
orodja , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , verbose = Prav
)
s = čas . števec_perf ( )
#konfiguriranje števca časa, da dobite čas, porabljen za celoten postopek
za q v vprašanja:
agent. teči ( q )
potekel = čas . števec_perf ( ) - s
#natisni skupni čas, ki ga je agent porabil za pridobivanje odgovorov
tiskanje ( f 'Serija je bila izvedena v {elapsed:0.2f} sekundah.' )
Izhod
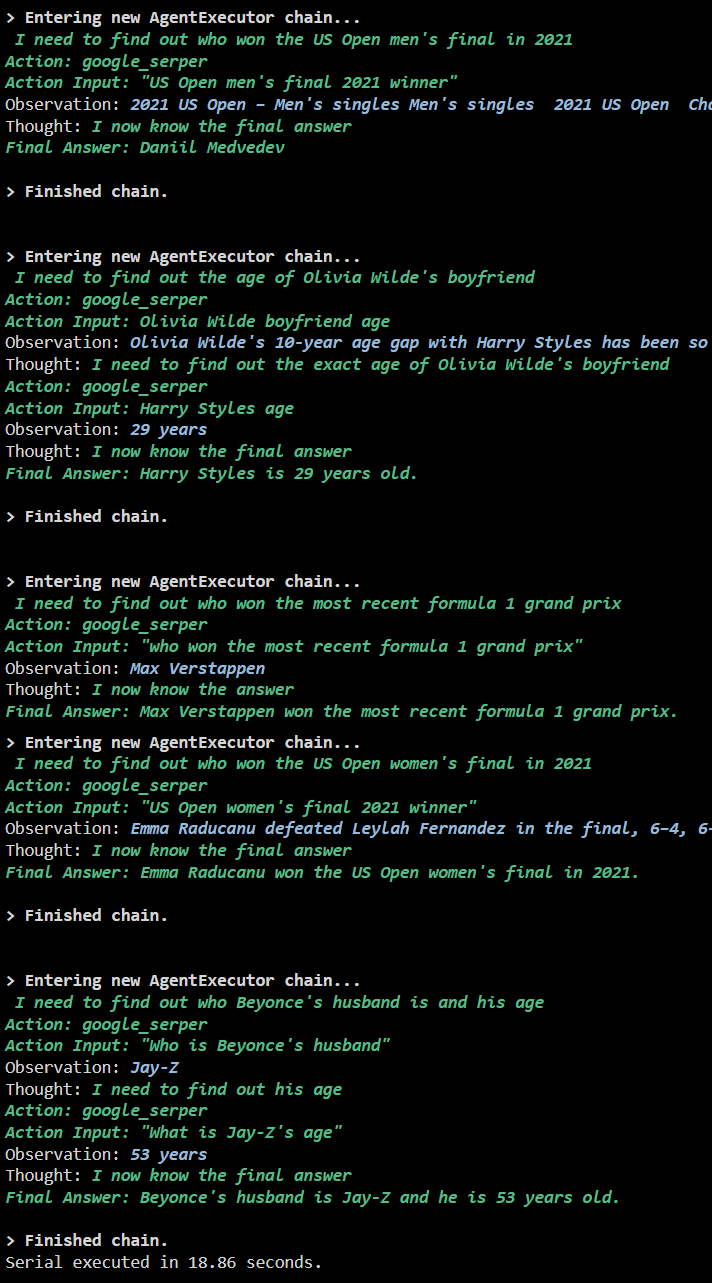
Naslednji posnetek zaslona prikazuje, da se na vsako vprašanje odgovori v ločeni verigi in ko je prva veriga končana, postane druga veriga aktivna. Serijska izvedba zahteva več časa, da dobite vse odgovore posebej:
2. način: Uporaba sočasnega izvajanja
Metoda sočasnega izvajanja prevzame vsa vprašanja in nanje dobi odgovore hkrati.
llm = OpenAI ( temperatura = 0 )orodja = load_tools ( [ 'google-header' , 'llm-matematika' ] , llm = llm )
#Konfiguriranje posrednika z zgornjimi orodji za hkratno pridobivanje odgovorov
agent = inicializiraj_agent (
orodja , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , verbose = Prav
)
#konfiguriranje števca časa, da dobite čas, porabljen za celoten postopek
s = čas . števec_perf ( )
naloge = [ agent. bolezen ( q ) za q v vprašanja ]
počakajte asyncio. zbrati ( *naloge )
potekel = čas . števec_perf ( ) - s
#natisni skupni čas, ki ga je agent porabil za pridobivanje odgovorov
tiskanje ( f 'Sočasno izvedeno v {elapsed:0.2f} sekundah' )
Izhod
Sočasno izvajanje ekstrahira vse podatke hkrati in traja veliko manj časa kot zaporedno izvajanje:
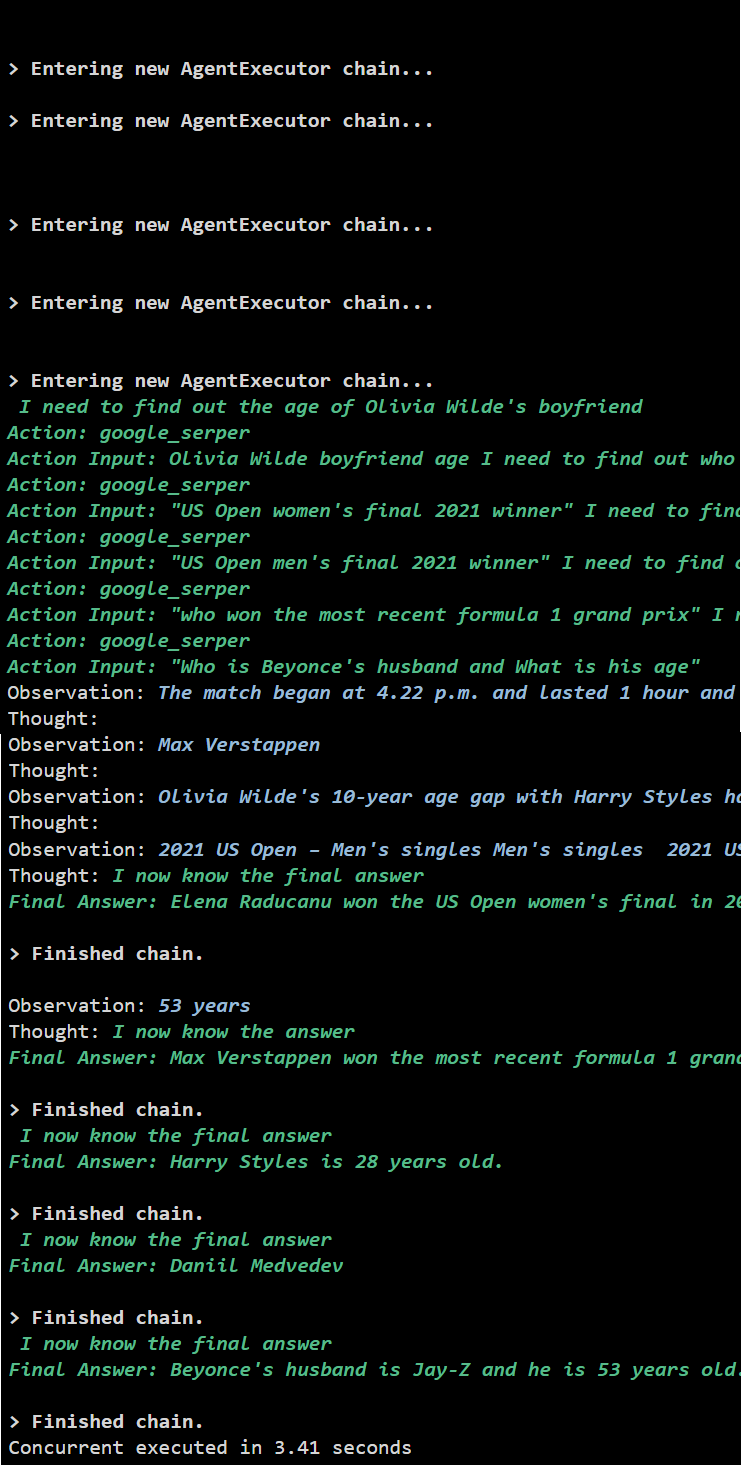
To je vse o uporabi agenta Async API v LangChainu.
Zaključek
Če želite uporabiti agenta Async API v LangChain, preprosto namestite module za uvoz knjižnic iz njihovih odvisnosti, da dobite knjižnico asyncio. Nato nastavite okolja z uporabo ključev OpenAI in Serper API, tako da se vpišete v njihove ustrezne račune. Konfigurirajte nabor vprašanj, povezanih z različnimi temami, in izvedite verige zaporedno in sočasno, da dobite čas njihove izvedbe. Ta priročnik podrobneje opisuje postopek uporabe agenta Async API v LangChain.