Ta vodnik bo prikazal postopek nalaganja verig iz LangChain Huba.
Kako dodati stanje pomnilnika v verigi z uporabo LangChain?
Stanje pomnilnika je mogoče uporabiti za inicializacijo verig, saj se lahko nanaša na nedavno vrednost, shranjeno v verigah, ki bo uporabljena pri vračanju izhoda. Če se želite naučiti postopka dodajanja stanja pomnilnika v verige z uporabo ogrodja LangChain, preprosto preglejte ta preprost vodnik:
1. korak: Namestite module
Najprej vstopite v postopek z namestitvijo ogrodja LangChain z njegovimi odvisnostmi z ukazom pip:
pip namestite langchain
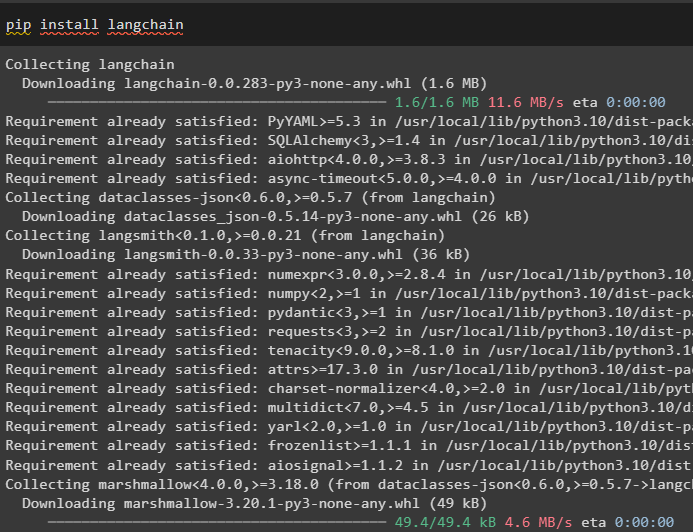
Namestite tudi modul OpenAI, da dobite njegove knjižnice, ki jih je mogoče uporabiti za dodajanje stanja pomnilnika v verigi:
pip namestite openai
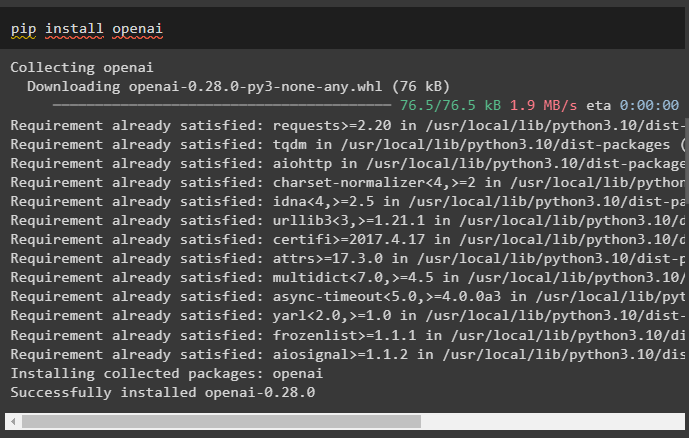
Pridobite ključ API iz računa OpenAI in nastavite okolje z uporabo, da lahko verige dostopajo do njega:
uvoz ti
uvoz getpass
ti . približno [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Ključ API OpenAI:' )
Ta korak je pomemben za pravilno delovanje kode.
2. korak: uvozite knjižnice
Ko nastavite okolje, preprosto uvozite knjižnice za dodajanje stanja pomnilnika, kot so LLMChain, ConversationBufferMemory in številne druge:
od Langchain. verige uvoz ConversationChainod Langchain. spomin uvoz ConversationBufferMemory
od Langchain. chat_models uvoz ChatOpenAI
od Langchain. verige . llm uvoz LLMChain
od Langchain. pozive uvoz PromptTemplate
3. korak: Gradnja verig
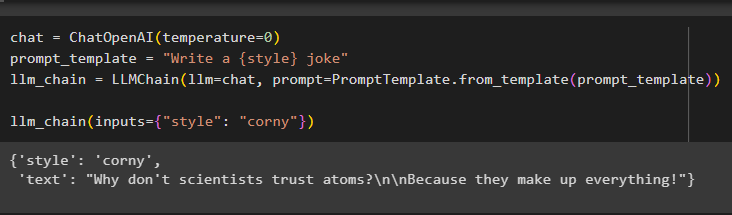
Zdaj preprosto zgradite verige za LLM z uporabo metode OpenAI() in predloge poziva z uporabo poizvedbe za klic verige:
klepet = ChatOpenAI ( temperaturo = 0 )prompt_template = 'Napiši {style} šalo'
llm_veriga = LLMChain ( llm = klepet , poziv = PromptTemplate. iz_predloge ( prompt_template ) )
llm_veriga ( vložki = { 'slog' : 'kuhan' } )
Model je prikazal rezultat z uporabo modela LLM, kot je prikazano na spodnjem posnetku zaslona:
4. korak: Dodajanje stanja pomnilnika
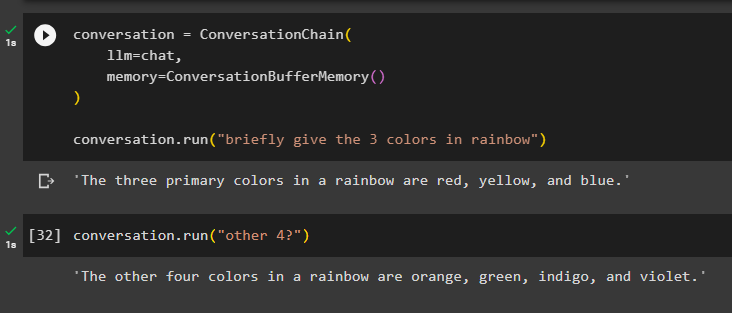
Tukaj bomo dodali stanje pomnilnika v verigo z uporabo metode ConversationBufferMemory() in zagnali verigo, da dobimo 3 barve iz mavrice:
pogovor = ConversationChain (llm = klepet ,
spomin = ConversationBufferMemory ( )
)
pogovor. teči ( 'na kratko pokaži 3 barve v mavrici' )
Model ima prikazane samo tri barve mavrice in kontekst je shranjen v pomnilniku verige:
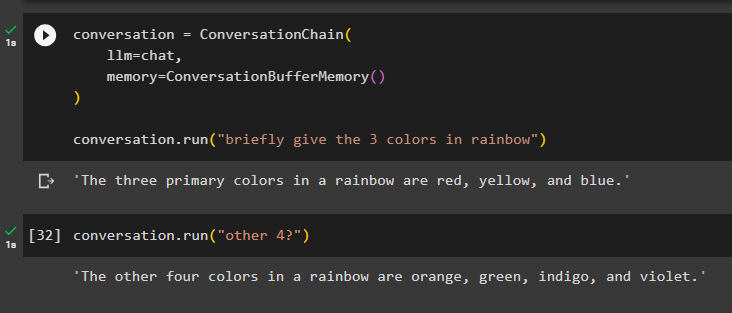
Tukaj izvajamo verigo z dvoumnim ukazom kot ' drugi 4? ” tako model sam pridobi kontekst iz pomnilnika in prikaže preostale mavrične barve:
pogovor. teči ( 'drugi 4?' )Model je naredil točno to, saj je razumel kontekst in vrnil preostale štiri barve iz mavričnega niza:
To je vse o nakladalnih verigah iz LangChain Huba.
Zaključek
Če želite dodati pomnilnik v verigah z uporabo ogrodja LangChain, preprosto namestite module za nastavitev okolja za gradnjo LLM. Po tem uvozite knjižnice, ki so potrebne za gradnjo verig v LLM, in ji nato dodajte stanje pomnilnika. Ko v verigo dodate stanje pomnilnika, verigi preprosto dajte ukaz, da dobite izhod, in nato dajte drug ukaz v kontekstu prejšnjega, da dobite pravilen odgovor. Ta objava je podrobneje opisala postopek dodajanja stanja pomnilnika v verige z uporabo ogrodja LangChain.