Ta vodnik bo razložil pajke seznamov v AWS.
Kaj so iskalniki seznamov v AWS?
Pajek je komponenta lepila AWS, ki se uporablja za pajkanje po lokaciji podatkov in sklepanje teh informacij nazaj v katalog. Informacije, ki jih zbira pajek, so lahko vrste podatkov, struktura sheme ali z drugimi besedami, zbira metapodatke. Pajek se lahko uporablja tudi s katalogom podatkov, ki se uporablja, ko se podatki premaknejo znotraj ekosistema Glue med uporabo opravil ETL itd.
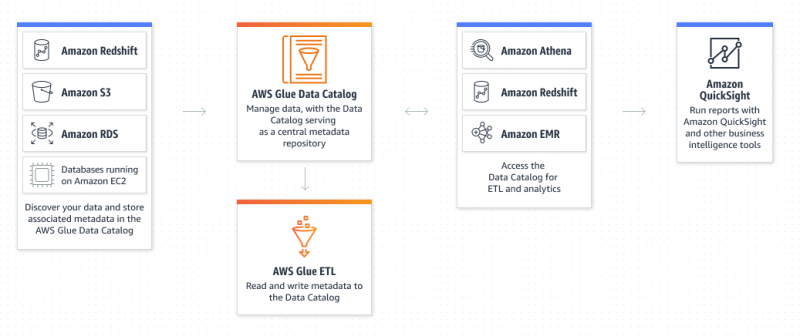
Kaj je Amazon Glue Service?
AWS Glue je storitev Amazon Extract Transform and Load, ki uporabniku omogoča organiziranje, lociranje, premikanje in preoblikovanje vseh podatkov. AWS Glue deluje brez strežnika, saj uporabniku ni treba zagotoviti in konfigurirati strežnikov ali upravljati življenjskih ciklov. Katalog podatkov in pajki so komponente AWS Glue, ki deluje kot trajni repozitorij metapodatkov:

Kako ustvariti pajka na AWS?
Če želite ustvariti pajka v AWS, obiščite storitev AWS Glue v upravljalni konzoli AWS:
Pojdite v ' Pajki ”, tako da kliknete njeno ime na levi plošči:
Kliknite na ' Ustvari pajka ” gumb:
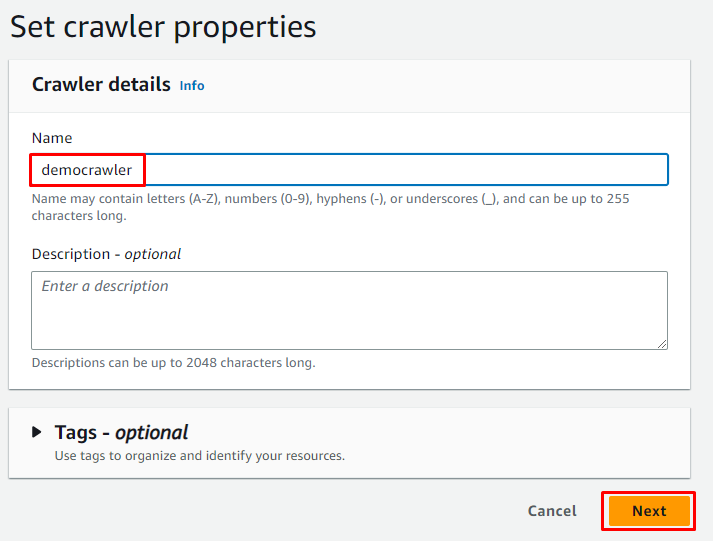
Vnesite ime pajka in kliknite » Naslednji ” gumb:
Izberite možnost preslikave za lepilne tabele in kliknite » Dodajte vir ” za pridobivanje podatkov iz:

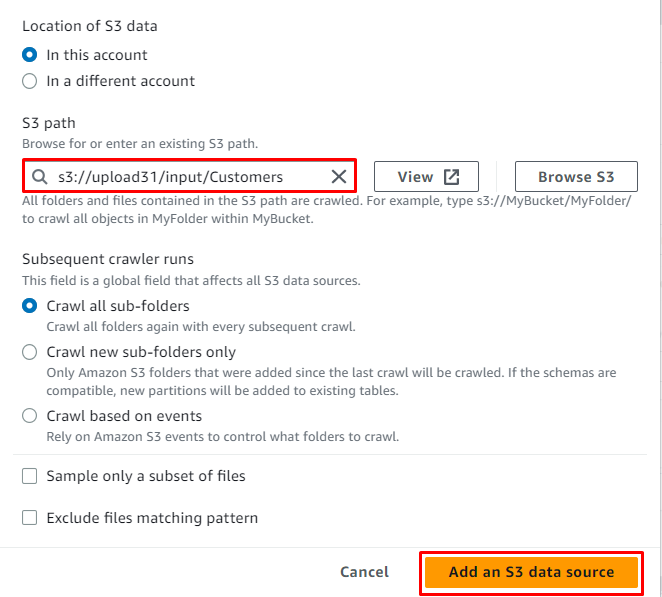
Izberite storitev S3 in kliknite » Brskajte po S3 ” za pridobitev lokacije vira:

Preprosto izberite mapo S3 in kliknite » Izberite ” gumb:

Ko je lokacija dodana viru, preprosto kliknite » Dodajte vir podatkov S3 ” gumb:
Kliknite na ' Naslednji ” gumb:

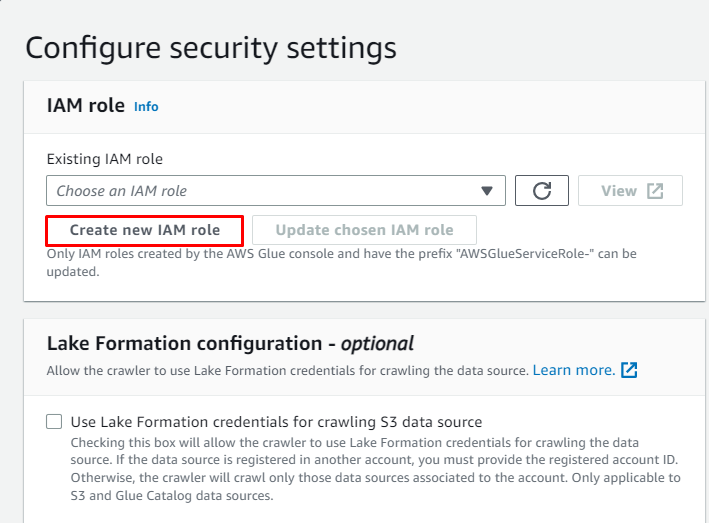
Kliknite na ' Ustvari novo vlogo IAM « gumb iz » Konfigurirajte varnostne nastavitve ” razdelek:
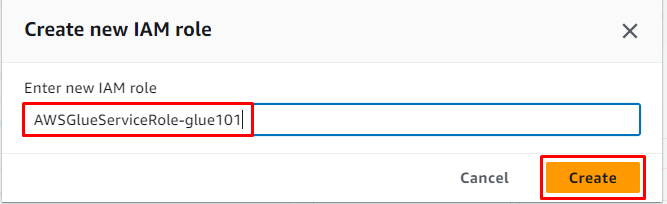
Vnesite ime vloge in kliknite » Ustvari ” gumb:
Po tem preprosto kliknite » Naslednji ” gumb:

Izberite ciljno bazo podatkov in vnesite ime, ki bo uporabljeno za tabelo:
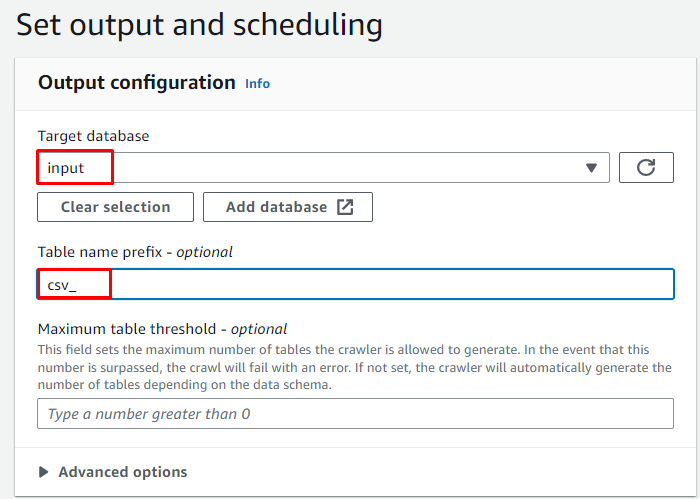
Načrtujte pajka za » Na zahtevo « in kliknite » Naslednji ” gumb:
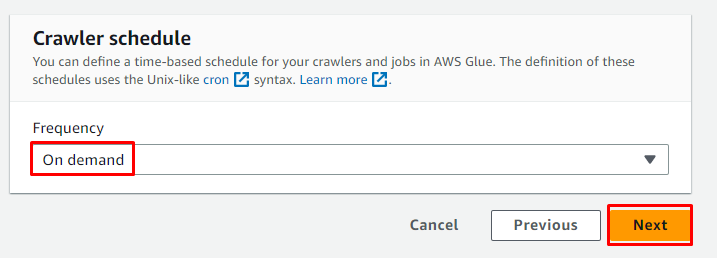
Preglejte konfiguracijo in kliknite » Ustvari pajka ” gumb:
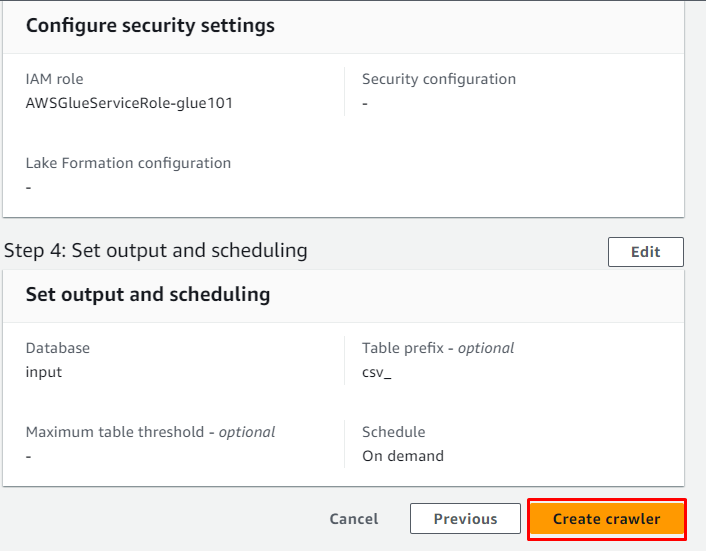
Pajek je bil uspešno ustvarjen in ga lahko uporabite za pridobivanje podatkov iz vira s klikom na ' Teči ” gumb:

To je vse o pajkih seznamov v AWS.
Zaključek
ListCrawler je komponenta storitve AWS Glue, ki jo je mogoče uporabiti za pajkanje informacij iz virov in vrnitev v katalog. Podatkovne kataloge in pajke je mogoče uporabiti za zbiranje podatkov za pridobitev informacij o podatkih, ki so znani kot metapodatki. Uporabnik lahko prav tako ustvari pajka iz AWS Glue, da pridobi podatke iz storitve S3 ali drugih virov in postavi ustvarjene tabele v bazo podatkov. V tem priročniku so razloženi ListCrawlerji v AWS in kako jih ustvariti.