Elasticsearch je robustna, zelo priljubljena rešitev za shranjevanje obsežnih, nestrukturiranih in polstrukturiranih podatkov. To je izključno baza podatkov NoSQL in uporablja popolnoma drugačen pristop za shranjevanje, upravljanje in pridobivanje podatkov. Shranjuje podatke v dokumentu v formatu JSON in uporablja ostale API-je za izvajanje različnih operacij na shranjenih podatkih.
V tem blogu bomo prikazali:
- Kako deluje Elasticsearch za shranjevanje in iskanje podatkov?
- Kaj so dokumenti Elasticsearch?
- Kako shraniti podatke v dokument Elasticsearch?
Kako deluje Elasticsearch za shranjevanje in iskanje podatkov?
Glavne komponente ali hierarhija Elasticsearch, ki se uporabljajo za shranjevanje podatkov, so navedene spodaj:
- Dokument: Dokument je glavni del Elasticsearch, ki shranjuje podatke v formatu JSON. Všeč mi je
- Indeksi: Indeksi se imenujejo indeksi. Gre za zbirko dokumentov. Tako kot v SQL se tudi to imenuje baza podatkov.
- Obrnjeni indeksi: Podpira zelo hitro iskanje po celotnem besedilu. Besedo shrani kot indeks in ime dokumenta kot sklic.
Kaj so dokumenti Elasticsearch?
Dokument Elasticsearch je enota za shranjevanje podatkov v formatu JSON. Tako kot v relacijskih bazah podatkov lahko dokument imenujemo tabela ali vrstica baze podatkov, ki je shranjena v nekem indeksu. Indeks ima lahko več dokumentov in se imenuje zbirka podatkov z več tabelami. Običajno hrani zapleteno podatkovno strukturo in podatke sterilizira v formatu JSON.
Poleg tega lahko vsak dokument vsebuje več polj, ki so » ključ:vrednost ” pari za shranjevanje podatkov tako kot ima tabela več stolpcev ali polj v relacijski bazi podatkov. Nato naj bi bili ti pari ključ-vrednost indeksirani na način, da se določi preslikava dokumenta. Preslikava nato definira vrsto podatkov dokumenta glede na podatke polja, kot so besedilo, lebdeča točka, geo točka, čas in še veliko več.
Elasticsearch nas nikoli ni zavezal k vnaprejšnji določitvi strukture polja indeksa in dokumenti imajo lahko različno strukturo polja v indeksu. Če pa je preslikava polja definirana za določen tip podatkov, morajo vsi dokumenti Elasticsearch v indeksu slediti istemu tipu preslikave. Če želite preveriti delovanje dokumenta za shranjevanje podatkov v Elasticsearch, pojdite skozi naslednji razdelek.
Kako shraniti podatke v dokument Elasticsearch?
Za shranjevanje podatkov v Elasticsearch mora uporabnik najprej ustvariti indeks. Nato določite polja za shranjevanje podatkov v dokumentu Elasticsearch. Za predstavitev pojdite skozi navedene korake.
1. korak: Zaženite Elasticsearch
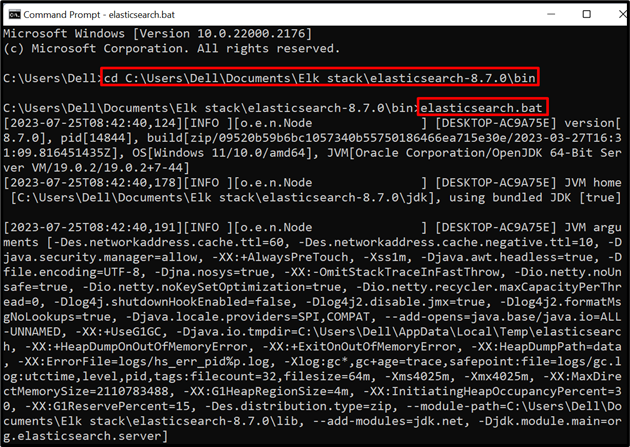
Če želite v sistemu zagnati bazo podatkov ali mehanizem Elasticsearch, zaženite sistemski terminal, kot je ukazni poziv. Po tem obiščite » koš ' mapo Elasticsearch prek ' cd ” ukaz:
cd C:\Uporabniki\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Po tem izvedite paketno datoteko Elasticsearch, da zaženete bazo podatkov v sistemu:
elasticsearch.bat
2. korak: Zaženite Kibana
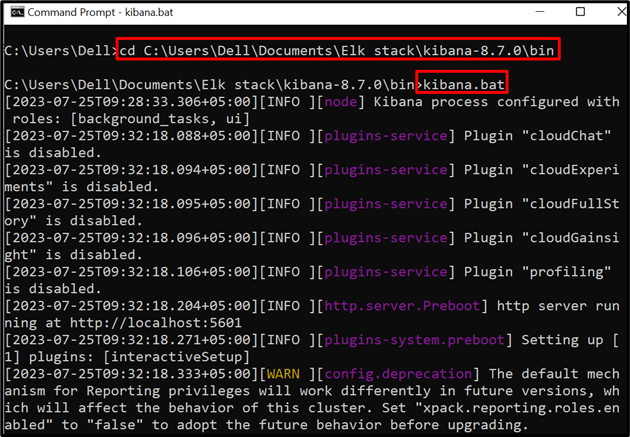
Nato izvedite Kibano v sistemu. Če želite to narediti, obiščite » koš ” iz ukaznega poziva:
cd C:\Uporabniki\Dell\Documents\Elk stack\kibana-8.7.0\bin
Nato zaženite spodnji ukaz, da začnete izvajati Kibano:
kibana.bat
Opomba: Če še niste namestili in nastavili Elasticsearch in Kibana v sistemu, se pomaknite do naših objav in si oglejte postopek po korakih za njuno namestitev v sistem.
Za Elasticsearch obiščite naš ' Namestite in nastavite Elasticsearch z .zip v sistemu Windows ' Članek. Če želite nastaviti Kibano v sistemu Windows, sledite navodilom » Nastavite Kibano za Elasticsearch ' Članek.
3. korak: Prijavite se v Kibano
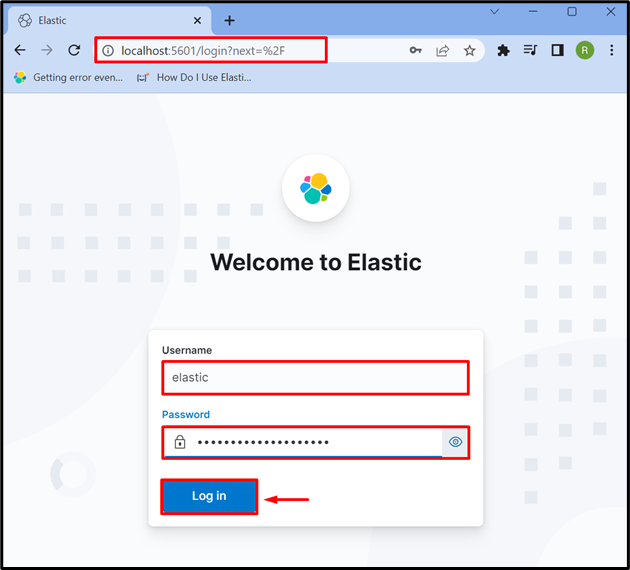
Po zagonu Kibane v sistemu se pomaknite do privzetega naslova Kibane “ lokalni gostitelj: 5601 « v brskalniku in vnesite poverilnice za prijavo Elasticsearch, kot je » elastična ” uporabnik in geslo. Po tem pritisnite ' Vpiši se ” gumb:
4. korak: Odprite Kibana »Dev Tool«
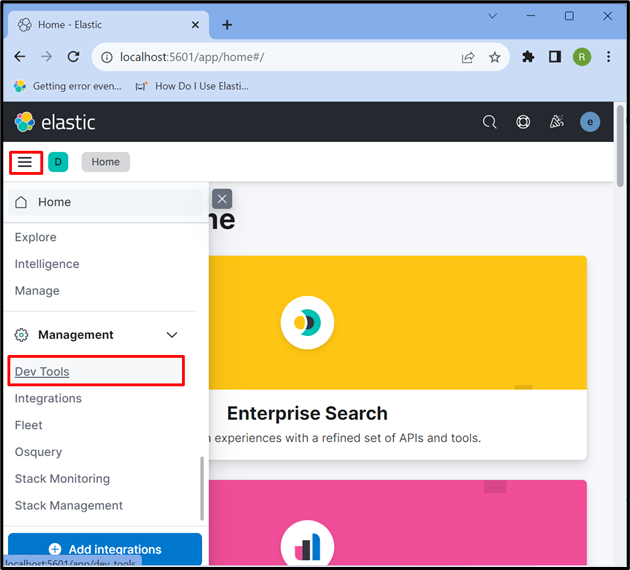
Po tem kliknite » Tri vodoravne palice ' in odprite Kibano ' Orodje za razvijalce ” za uporabo API-jev za shranjevanje, pridobivanje in posodabljanje podatkov:
5. korak: Ustvarite indeks
Zdaj ustvarite nov indeks z uporabo ' PUT /
Rezultat kaže, da je ' zaposleni-podatki Indeks je uspešno ustvarjen:
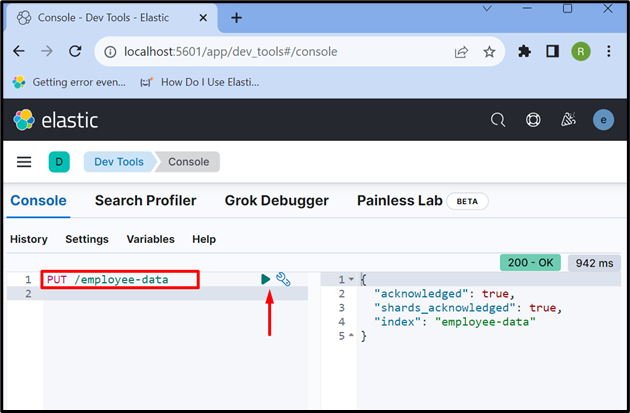
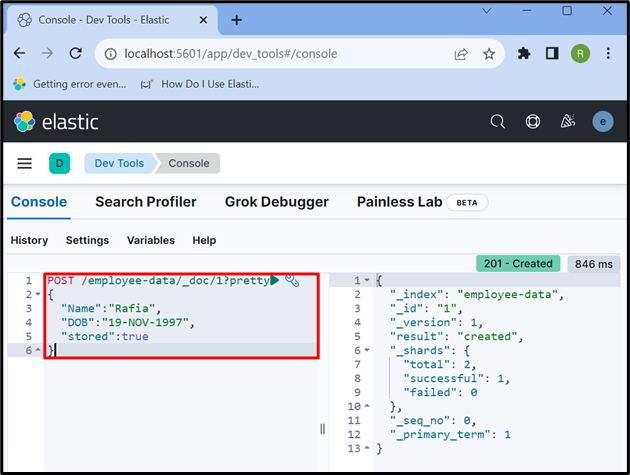
6. korak: Vstavite podatke v dokument
Zdaj uporabite » OBJAVI ” API za shranjevanje podatkov v indeksu. V spodnji zahtevi ' zaposleni-podatki ' je indeks Elasticsearch, ' _doc ” se uporablja za shranjevanje podatkov v dokumentu Elasticsearch in “ 1 ” je ID:
OBJAVI / zaposleni-podatki / _doc / 1 ?lepa{
'Ime' : 'Rafija' ,
'DOB' : '19-NOV-1997' ,
'shranjeno' :prav
}
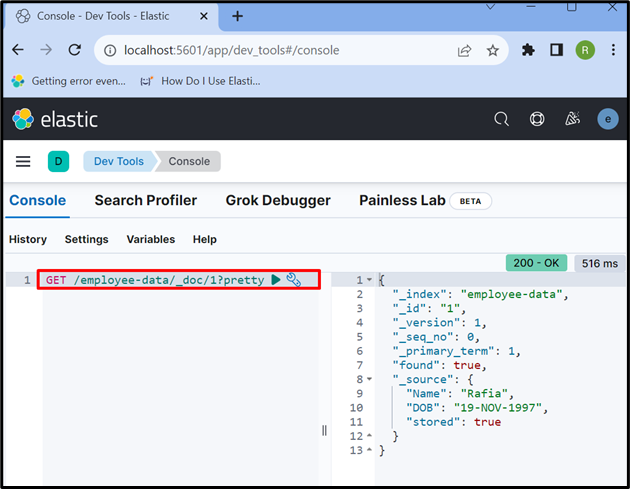
7. korak: Pridobite podatke iz dokumenta Elasticsearch
Za dostop do podatkov iz indeksa ali dokumenta Elasticsearch uporabite » DOBITI ” API, kot se uporablja spodaj:
DOBITI / zaposleni-podatki / _doc / 1 ?lepa
Izhod kaže, da smo uspešno ekstrahirali podatke iz dokumenta Elasticsearch z ID-jem ' 1 ”:
To je vse o dokumentu Elasticsearch.
Zaključek
Dokument Elasticsearch se običajno uporablja za shranjevanje podatkov v formatu JSON. Tako kot v relacijskih bazah podatkov lahko dokument imenujemo vrstica, ki je shranjena v nekem indeksu. Ti indeksi imajo lahko več dokumentov, tako kot imajo zbirke podatkov različne tabele. Ti dokumenti vsebujejo več polj, ki so » ključ:vrednost ” pari za shranjevanje podatkov. Ta članek je pokazal, kaj so dokumenti Elasticsearch in kako delujejo v Elasticsearch.