Sintaksa:
Drseče povprečje lahko izračunamo na različne načine, ki so naslednji:
1. način:
NumPy. cumsum ( )Vrne vsoto elementov v dani matriki. Drseče povprečje lahko izračunamo tako, da rezultat funkcije cumsum() delimo z velikostjo matrike.
2. način:
NumPy. in . povprečje ( )Ima naslednje parametre.
a: podatki v obliki niza, ki jih je treba povprečiti.
os: njegov podatkovni tip je int in je neobvezen parameter.
teža: je tudi matrika in izbirni parameter. Lahko je enake oblike kot 1-D oblika. V primeru enodimenzionalnega mora imeti enako dolžino kot niz 'a'.
Upoštevajte, da se zdi, da v NumPy ni standardne funkcije za izračun drsečega povprečja, tako da je to mogoče storiti z drugimi metodami.
3. način:
Druga metoda, ki jo je mogoče uporabiti za izračun drsečega povprečja, je:
npr. zviti ( a , v , način = 'poln' )V tej sintaksi je a prva vhodna dimenzijska vrednost, v pa druga vhodna dimenzijska vrednost. Način je neobvezna vrednost, lahko je polna, enaka in veljavna.
Primer št. 01:
Zdaj, da pojasnimo več o drsečem povprečju v Numpyju, naj navedemo primer. V tem primeru bomo vzeli drseče povprečje matrike s funkcijo konvolucije NumPy. Torej bomo vzeli matriko 'a' z 1,2,3,4,5 kot njene elemente. Zdaj bomo poklicali funkcijo np.convolve in shranili njen rezultat v našo spremenljivko 'b'. Po tem bomo natisnili vrednost naše spremenljivke 'b'. Ta funkcija bo izračunala premikajočo se vsoto naše vhodne matrike. Izpis bomo natisnili, da vidimo, ali je naš izpis pravilen ali ne.
Nato bomo naš izhod pretvorili v drseče povprečje z isto metodo konvolve. Za izračun drsečega povprečja bomo morali samo drsečo vsoto deliti s številom vzorcev. Toda glavna težava tukaj je, ker je to drseče povprečje, število vzorcev se spreminja glede na lokacijo, na kateri smo. Da bi rešili to težavo, bomo preprosto ustvarili seznam imenovalcev in to moramo spremeniti v povprečje.
V ta namen smo inicializirali drugo spremenljivko »denom« za imenovalec. Preprosto je za razumevanje seznama z uporabo trika obsega. Naš niz ima pet različnih elementov, tako da bo število vzorcev na vsakem mestu šlo od enega do pet in nato nazaj od pet do enega. Torej bomo preprosto sešteli dva seznama in ju shranili v naš parameter »denom«. Zdaj bomo natisnili to spremenljivko, da preverimo, ali nam je sistem dal prave imenovalce ali ne. Po tem bomo našo premikajočo se vsoto razdelili z imenovalci in jo natisnili tako, da bomo izhod shranili v spremenljivko 'c'. Izvedimo kodo, da preverimo rezultate.
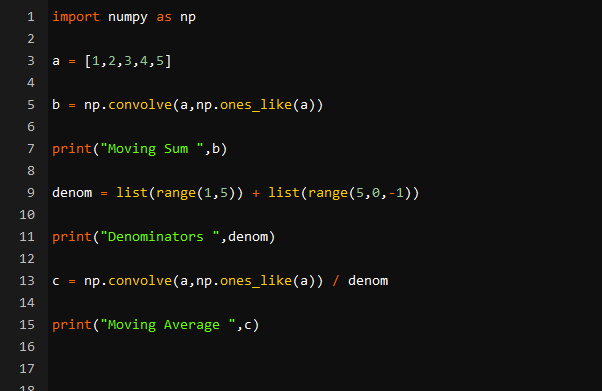
uvoz numpy kot npr.a = [ 1 , dva , 3 , 4 , 5 ]
b = npr. zviti ( a , npr. ones_like ( a ) )
tiskanje ( 'Gibljiva vsota' , b )
ime = seznam ( obseg ( 1 , 5 ) ) + seznam ( obseg ( 5 , 0 , - 1 ) )
tiskanje ( 'Imenovalci' , ime )
c = npr. zviti ( a , npr. ones_like ( a ) ) / ime
tiskanje ( 'Drseče povprečje' , c )
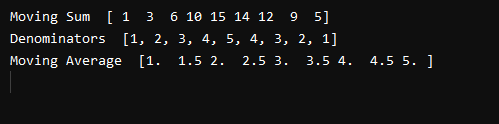
Po uspešni izvedbi naše kode bomo dobili naslednji rezultat. V prvi vrstici smo natisnili »Glebno vsoto«. Vidimo lahko, da imamo »1« na začetku in »5« na koncu niza, tako kot smo imeli v prvotnem nizu. Ostala števila so vsote različnih elementov našega niza.
Na primer, šest v tretjem indeksu matrike izhaja iz seštevanja 1, 2 in 3 iz naše vhodne matrike. Deset v četrtem indeksu izhaja iz 1, 2, 3 in 4. Petnajst izhaja iz seštevka vseh števil skupaj in tako naprej. Zdaj smo v drugi vrstici našega izpisa natisnili imenovalce našega niza.
Iz našega rezultata lahko vidimo, da so vsi imenovalci natančni, kar pomeni, da jih lahko delimo z našo premikajočo se matriko vsot. Zdaj se premaknite na zadnjo vrstico izhoda. V zadnji vrstici lahko vidimo, da je prvi element naše matrike drsečega povprečja 1. Povprečje 1 je 1, tako da je naš prvi element pravilen. Povprečje 1+2/2 bo 1,5. Vidimo lahko, da je drugi element naše izhodne matrike 1,5, tako da je tudi drugo povprečje pravilno. Povprečje 1,2,3 bo 6/3=2. Prav tako naredi naš izhod pravilen. Na podlagi rezultatov lahko torej rečemo, da smo uspešno izračunali drseče povprečje matrike.
Zaključek
V tem priročniku smo izvedeli o drsečih povprečjih: kaj je drseče povprečje, za kaj se uporablja in kako izračunati drseče povprečje. Podrobno smo ga preučili tako z matematičnega kot programskega vidika. V NumPy ni posebne funkcije ali postopka za izračun drsečega povprečja. Vendar pa obstajajo različne druge funkcije, s pomočjo katerih lahko izračunamo drseče povprečje. Naredili smo primer za izračun drsečega povprečja in opisali vsak korak našega primera. Drseča povprečja so uporaben pristop za napovedovanje prihodnjih rezultatov s pomočjo obstoječih podatkov.